Concurrent (Eszamanlı) Programlama ve Race Condition Tehlikesi
Programlama ve programlama tekniklerinin gelişimi, teknolojinin gelişimiyle doğru orantılı olarak değişim göstermiştir. Kullanılan donanımlar daha güçlü özellikler sundukça bu onların tasarımlarını da komplike bir hale getirmiş ve bu donanımlar üzerinde çalışan yazılımların da ona uygun şekilde yeniden tasarlanmalarını zorunlu kılmıştır. Örneğin bugün multi-core yahut multi-processor (İkisi arasında fiziksel fark mevcuttur. Multiprocessor birden fazla fiziksel işlemciyi ifade ederken, multi-core aynı fiziksel işlemci içerisindeki birden fazla işlem birimi çekirdeğini ifade eder.) sistemler üzerinde çalışan işletim sistemleri için yazılım geliştiren kişi, multitasking özelliği olmayan DOS için yazılım geliştiren bir kişiden daha fazla şeyi göz önünde bulundurmak, yazılımının tasarımını ona göre yapmak zorundadır.
Çok çekirdekli yahut çok işlemcili sistemler ile beraber concurrency (eşzamanlılık) terimi de anlam kazanmaya başladı. Çünkü bu tür işlemci teknolojileri aynı zaman diliminde birden fazla komutu paralel olarak çalıştırabilme yeteneklerine sahipler. Esas problemi oluşturan kısım işlemci tarafından ziyade verilerin depolandığı belleğin tek olması ve bu belleğe erişimin işlemciler tarafından aynı veriyolu (bus) üzerinden yapılıyor olmasıdır. Böyle bir durumda bellek bir paylaşılan kaynak konumundadır. Paylaşılan bir kaynağa, eşzamanlı çalışan işlemcilerin erişmeye çalışması işin programlama kısmında baş edilmesi gereken bir dizi problemi beraberinde getirir. Yalnız bu durum sorunun en büyük sebebi olsa da tek sebebi değildir. Gelişen işletim sistemi tasarımlarının paylaşımlı kaynağa erişmekte getirdiği benzer problemler de mevcut. Buna yazının ilerleyen kısmında sırası geldiğinde değineceğim. Ve o nokta da oldukça önem taşımaktadır. Her ne kadar da multiprocessor sistemler söz konusu olsa da uniprocessor (tek işlemcili) sistemlerde birçok modern işletim sistemi multi-threading sağlamaktaydı. Şimdilik not olarak geçeyim.
Race Condition
Race condition terimi iki bağımsız eş sürecin (Process) aynı kaynak üzerine aynı zaman diliminde erişmeye çalışması sonucu bir sürecin diğerinden önce o kaynağa erişip farklı sonuçlar üretmesine yol açan durumu tanımlamaktadır. Bu terimin genel bilinen bir Türkçe karşılığı yok. Biraz Türkçe’ye doğrudan çevrilmesi sıkıntılı manasız bir söz öbeğine sebebiyet verebilir. O yüzden ben de buna race condition demekle yetineceğim. Ancak şunu söyleyebilirim. İki eş sürecin aynı zaman diliminde bir kaynağa erişmesini bir yarışa, bir mücadeleye benzetirsek bu mücadele durumunun race condition terimiyle olan bağlantısını kafanızda sanırım bir yere oturtabilirsiniz.
Her ne kadar da çoklu işlemcilerde eş zamanlılık mevcutsa da söz konusu tek bir kaynağa aynı veriyolu üzerinden erişim olduğundan iki eş süreçten biri aynı zaman diliminde kaynağa erişim sağlamaktadır. Yalnız bu işlemler nanosaniyeler ölçeğinde olup bitmektedir. 1 saniyenin 1000.000.000 (bir milyar) nanosaniyeye eşit olduğunu unutmayın.
Race condition’ı daha sıkıntılı hale getiren bir durum daha vardır ki o da race condition’ların rastgele meydana gelmesidir. Race condition’ların ne zaman oluşacağını tahmin edemezsiniz. Bir program yeterince şanslı ise race condition oluşmadan belki haftalarca düzgün bir şekilde çalışabilir. Ancak bu onun hiç oluşmayacağı anlamına gelmez. Bu kesinlikle garanti değildir. Çünkü race condition’a zemin hazırlayan şartlar tamamen işlemciler üzerinden çalışan diğer süreçlerin zamanlanmasına bağlıdır. Race condition oluştuğunda şartlar öyle bir haldedir ki her iki işlemci aynı süreci aynı anda işletmeye çalışmaktadır. Eğer işletim sistemi o sırada farklı süreçleri çalıştırmaktaysa elbette bu ihtimal sıfıra yakın ancak sıfır değildir.
Şimdi bu anlatılanı bir kod üzerinde örnekleyeyim. Örnekte bir adet paylaşımlı bir değişken olsun. Ve eşzamanlı çalışacak 2 adet sürecimiz olsun. Yaptığı iş bu paylaşımlı değeri +1 kadar arttırmak olsun.
int g_sharedValue = 0;
void work()
{
int iteration=5;
while (iteration-- > 0)
{
g_sharedValue++;
}
}
void start()
{
const int WORKER_COUNT=5;
for (int i=0;i<WORKER_COUNT;i++)
{
create_worker(work);
}
}
Şimdi yukarıdaki misal verilen kod 5 farklı iş parçacığı (Thread) içinde work adında bir fonksiyonu çalıştırıyorlar. Ve create_worker fonksiyonunu da her bir work fonksiyonunu farklı processorlar üzerinde çalıştırdığını düşünün yeter. Dikkatinizi esas işi yapan work fonksiyonuna verin. Şimdi normal şartlarda beklentimiz şu şekilde olur. Elimizde 5 adet thread (iş parçacığı) var. Ve bu 5 farklı süreç kendi içinde 5’er defa paylaşımlı olan g_sharedValue adlı değişkenimizi +1 arttırıyor. Bizim beklentimiz bu program çalışıp sonlandığında g_sharedValue değişkeninin 25 değerini tutuyor olması. Ancak programı defalarca çalıştırdığımızda şu şekilde sonuçlar almamız olasıdır.
1. çalışma: 25
2. çalışma: 25
3. çalışma: 25
4. çalışma: 25
5. çalışma: 25
6. çalışma: 23
7. çalışma: 25
8. çalışma: 25
9. çalışma: 24
10. çalışma: 25
Çoğunlukta beklediğimiz sonucu alsak da aralarda çok farklı sonuçlar alabildik. İşte bu duruma sebebiyet veren durum Race condition’ın tam olarak karşılığıdır. Peki nasıl oluyor da döngü içinde çalışan bu kod eksik sayabiliyor? Bunu yukarıda yazıya giriş kısmında bahsettiğim olayı birazcık grafiğe dökerek biraz detaylandırarak anlatmak gerekecek.
İşlemciler programladığımız işlemleri yapmak için yazdığımız programlara karşılık gelen bir dizi makine komutu dizilerini çalıştırmak durumundadırlar. Her ne kadar da biz makine komutlarına göre yüksek seviye sayılacak dillerde bu işlemleri bir bütün halinde çalışacağını düşünsek de bu kodların makine kodu karşılıkları birkaç adımdan meydana gelebilir.
Yukarıdaki örneğimizde bir değişkeni bir arttıran kod işlemcinin perspektifinden şu adımlarla gerçekleşir. Bu adımlar işlemci mimarisinden mimarisine değişse de genel olarak hemen hepsinde aynı yol izlenir. İşlemciler bir bellek bölgesinde bir değer üzerinde değişikliğe gideceği zaman bunu doğrudan bellek üzerinde yapamazlar. Önce bellek bölgesinden veriyi içsel yazmaçlarına (Registers) almalı (Load), yazmaçlar üzerinde gerekli değişiklik yapıldıktan sonra tekrar bellek bölgesine yazılmalıdır (Store).
Yani g_sharedValue++ operasyonu işlemci üzerinde şu adımlarla gerçekleşir.
1 – REGISTER1 = [g_sharedValue] //g_sharedValue değişken adresindeki değeri 1 nolu yazmaca yükle
2 – REGISTER1 = REGISTER1 + 1 //yazmaç değerini 1 arttır.
3 – [g_sharedValue] = REGISTER1 //yazmaçtaki değeri geri bellek bölgesine depola.
Şimdi baktığımızda bizim açımızdan tek adımda halledilen bir kodun esasen 3 ayrı adımdan meydana geldiğini gördük. Bu noktada bir kavramdan daha bahsetmem gerek. O da Atomicity (Bölünmezlik) dir. Atomicity yani bölünmezlik işlemci üzerindeki bir makine komut çalışırken onu hiçbir başka komutun araya girip bölememesi demektir. Örneğin yukarıdaki her bir adım birer atomic operasyondur. Yani çalışmaları asla bölünemez.
![]() DİKKAT: Bazı tek instruction (buyruk)’dan oluşan kimi komutlar atomik gibi görünse de içsel olarak yaptıkları birden fazla iş söz konusu olduğunda atomik olamazlar. Örneğin doğrudan bellek adresleri üzerinde işlem yapan arttırma, azaltma, ekleme, çıkarma, yer değiştirme komutları gibi. Bu komutların atomik olabilmesi için özel olarak veriyolu (bus) kilitlenmelidir.
DİKKAT: Bazı tek instruction (buyruk)’dan oluşan kimi komutlar atomik gibi görünse de içsel olarak yaptıkları birden fazla iş söz konusu olduğunda atomik olamazlar. Örneğin doğrudan bellek adresleri üzerinde işlem yapan arttırma, azaltma, ekleme, çıkarma, yer değiştirme komutları gibi. Bu komutların atomik olabilmesi için özel olarak veriyolu (bus) kilitlenmelidir.
Race condition problemimizin derinliklerine indiğimizde meselenin atomicity konusunda indirgendiğini görmüş olmalısınız. Eğer yazdığımız bir kod aslında bölünebilir birkaç adıma ayrılabiliyorsa bir komut tamamlanmadan belli şartlar oluştuğunda pek ala çalışması kesilebilir. Yukarıdaki örnek kodun neden eksik sayabileceğine ilişkin race condition durumunu bir grafik üzerinde detaylandıralım.

Yukarıdaki grafik iki farklı CPU üzerinde çalışan eş süreçlerin bir kaynağa erişim zamanlarını göstermektedir. Yukarıda adımlara böldüğümüz operasyonları grafiğe döktüğümüzde Race condition’ın nasıl oluştuğunu daha rahat kavrayabileceksiniz.
Grafikte görüldüğü üzere iki farklı CPU üzerinde çalışan eş süreç bir kaynağa (P) değerini içsel yazmacına yüklemek amacıyla erişmek istiyor. Burada CPU2 bu okuma isteğini CPU1’den önce gerçekleştirdiğinde CPU2 veriyolunu sahiplenmiş olur. Bu da bu eş süreçlerden bir diğerini çalıştıran CPU1’in komutunu diğerine göre geriye ötelemesine sebep olmaktadır. CPU1 de bu bellek bölgesini CPU2’den geç okuduğundan sonraki komutlar da paylaşılan bellek bölgesindeki verinin beklenmeyen biçimde değişmesine sebep olacaktır. Başlangıç değeri P=5 olan bu değişkenin sırayla t zamanda yapılan işlemlerini ve her adımdaki durumunu yazalım. Tabloyu okurken yukarıdaki grafiği referans olarak kullanmanız yararlı olacaktır.
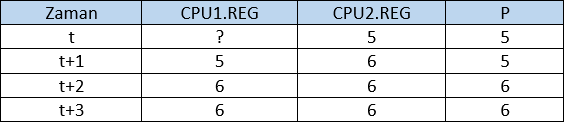
Tabloda grafikte zaman dilimlerine bölünmüş işlem grafiğinin zaman dilimlerindeki register ve hedef değişken değerlerini göstermektedir. Dananın kuyruğunun esas koptuğu yer t+2 zaman dilimi. Dikkat ederseniz CPU2 yazmacındaki değeri arttırıp geri hedef bellek bölgesine bu değeri yazmış durumdadır. Ancak belleğe yazıldığı anda henüz CPU1 önceden yazmacına aldığı 5 değerini yeni arttırmıştır. Bu durumda CPU1’in sonraki komutu olan yazmaç değerinin bellek bölgesine tekrar yazılması sonucu yine belleğe 6 değeri yazılacaktır. Halbuki senkron çalışan 2 süreçten sonra 5 olan başlangıç değeri 2 sürecin çalışıp bitmesi sonucu P değerinin 7 olması gerekiyordu. İşte t+2 noktası race condition’ın kritik gerçekleşme noktasını oluşturmaktadır. Ve yinelemek gerekiyor ki bu işlemler nanosaniyeler içerisinde olup bitmektedir. Haliyle bu durum programcı açısından tespit etmesi oldukça zor bir iştir.
Race condition’lar zamanlama ile alaklı şeyler olduklarından debug (hata ayıklama) yöntemleriyle tespit edilemezler. Çünkü debugging zaman maliyeti sebebiyle başlı başına race condition’ı engelleyecek bir unsurdur. Eğer bir kodda race condition sebepli bir bozukluk zamanla gözlenebiliyorsa bunu çözmek kabul edelim ki zorlu bir süreç olacaktır. Hele ki yazılım git gide büyümüş, komplike bir hal almış durumda bir yazılımsa durum daha vahim hale gelir. Bu yüzden programcı bu hataya düşmeden yazılımını gerekli kalitede kodlamak durumundadır. Ve yazılımı thread-safe halde yazmaya harcadığınız vakit, race condition oluşmuş yazılımı düzeltmeye çalışmaktan kat ve kat daha az olacaktır.
Canlı Bir Örnek
Bu kadar teorik anlatımdan sonra sizin için race condition oluşturan çalışan bir örnek göstermek istiyorum. Bu iş için ufak bir demo programı yazdım. Örnekleri bu program üzerinden göstereceğim. Programın kaynak kodlarına https://gist.github.com/0ffffffffh/cf93ed82d86dffe8ddb8#file-rcdemo-c linkinden ulaşabilirsiniz. Program birden çok senaryoyu test etmek için hazırlandı. Program basitçe paylaşımlı bir değişkeni birden fazla iş parçacığı (thread) içinde artırma / eksiltme işlemi yapıyor. Haricen aşağıdaki opsiyonlardan gördüğünüz gibi bu thread’leri sistemdeki aktif işlemci çekirdeklerini eşit şekilde paylaştırarak çalıştırabiliyor, yahut sadece tek işlemcili bir sistemi simule ederek çalışabiliyor.
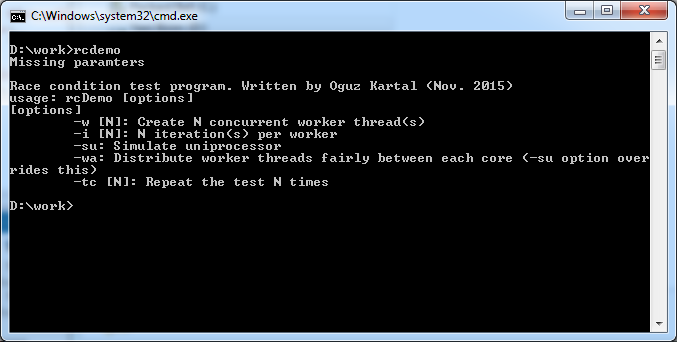
Program çeşitli opsiyonlara sahip.
-w [N]: kaç adet thread (iş parçacığı) kullanılacaksa N değeri yerine thread adedi.
-i [N]: thread içerisinde çalışan artırma/eksiltme iterasyonunun sayısı
-su: eğer bu parametre verilirse program tek işlemcili bir sistemi simule eder
-wa: Bu parametre sayısı verilen thread’leri eşit olarak bilgisayarda olan tüm çekirdeklere paylaştırır. Bu çalışan kodun concurrent (Eşzamanlı) çalışmasını garanti almak için kullanılabilir
-tc: Verilen parametrelerle testin kaç defa tekrar edileceğini bildirir.
Programın temel gayet basit. İşi esas yapan kod parçası aşağıda bulunmaktadır. İnceleyebilirsiniz. workerMethod içerisindeki kod paylaşılan değişkeni artırıp azaltma işlemine tabi tutuyor. Böylece bu değerin sıfır olup olmama durumuna göre bir race condition oluşup oluşmadığına dair bilgi sahibi olacağız. İsterseniz kod parçasını geçebilirsiniz.
LONG sharedValue = 0;
typedef struct _workerInfo
{
DWORD iteration;
LONG *pShared;
}workerInfo;
DWORD WINAPI workerMethod(void *p)
{
workerInfo *pWi = (workerInfo *)p;
LONG *pVal = pWi->pShared;
DWORD iteration = pWi->iteration;
while (iteration-- > 0)
{
(*pVal)++;
(*pVal)--;
}
return 0;
}
void startWorkers(DWORD id,DWORD workerCount, DWORD iterationPerWorker, BOOL simulateUniprocessor, BOOL coreAffinity)
{
DWORD processorCount,affMask, processorId=0, dummy;
workerInfo wi;
SYSTEM_INFO sysInfo;
HANDLE *threads = NULL;
GetSystemInfo(&sysInfo);
processorCount = simulateUniprocessor ? 1 : sysInfo.dwNumberOfProcessors;
if (simulateUniprocessor && !coreAffinity)
coreAffinity = TRUE;
threads = (HANDLE *)HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, sizeof(HANDLE) * workerCount);
wi.iteration = iterationPerWorker;
wi.pShared = &sharedValue;
if (!threads)
{
printf("handle list could not allocated!\n");
return;
}
sharedValue = 0;
printf("\n=== Test#%d is staring ===\n", id);
for (int i = 0; i < workerCount;i++)
{
threads[i] = CreateThread(NULL, 0, (LPTHREAD_START_ROUTINE)workerMethod, &wi, 0, &dummy);
if (coreAffinity)
{
affMask = 1 << processorId;
if (processorId == processorCount - 1)
processorId = 0;
else
processorId++;
SetThreadAffinityMask(threads[i], affMask);
}
}
WaitForMultipleObjects(workerCount, (const HANDLE *)threads, TRUE, INFINITE);
for (int i = 0; i < workerCount; i++)
CloseHandle(threads[i]);
HeapFree(GetProcessHeap(), 0, threads);
printf("=== Test#%d finished. Expected Value: 0, Actual sharedValue : %d ===\n\n\n",id, sharedValue);
}
Öncelikle ufak bir testle başlayalım.
Test#1) Program Opsiyonları: -w 5 -i 50 -wa
Test will be running using 5 Worker Threads with 50 iteration per worker. Uniprocessor simulation is off, and Worker distribution is on === Test#1 is staring === === Test#1 finished. Expected Value: 0, Actual sharedValue : 0 === All done
5 thread’in çalıştığı ve her birinde 50 iterasyonun çalıştığı 1 adet testte herhangi bir race condition’a rastlamadık. En başta da dediğim gibi race condition oluşup oluşmamasını tahmin edemeyiz. İlk çalışmamızda herhangi bir race condition’a sebebiyet verecek durum oluşmayacak kadar şanslıydık. Şimdi biraz daha stresi arttıralım.
Test#2) Program Opsiyonları: -w 10 -i 500 -wa -tc 6
Test will be running using 10 Worker Threads with 500 iteration per worker. Uniprocessor simulation is off, and Worker distribution is on === Test#1 is staring === === Test#1 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#2 is staring === === Test#2 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#3 is staring === === Test#3 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#4 is staring === === Test#4 finished. Expected Value: 0, Actual sharedValue : 3 === === Test#5 is staring === === Test#5 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#6 is staring === === Test#6 finished. Expected Value: 0, Actual sharedValue : 0 === All done
10 thread’li 500 iterasyonlu testi 6 defa yapılmasını istedik. Bu defa çoğunluk olarak beklenen sonuç almış olsak da 4 numaralı test sonucuna baktığımızda açık bir şekilde race condition oluştuğunu görebiliyoruz. İterasyon sıklığını biraz daha arttıralım.
Test#3) Program Opsiyonları: -w 10 -i 2000 -wa -tc 6
Test will be running using 10 Worker Threads with 2000 iteration per worker. Uniprocessor simulation is off, and Worker distribution is on === Test#1 is staring === === Test#1 finished. Expected Value: 0, Actual sharedValue : 30 === === Test#2 is staring === === Test#2 finished. Expected Value: 0, Actual sharedValue : 6 === === Test#3 is staring === === Test#3 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#4 is staring === === Test#4 finished. Expected Value: 0, Actual sharedValue : 17 === === Test#5 is staring === === Test#5 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#6 is staring === === Test#6 finished. Expected Value: 0, Actual sharedValue : 51 === All done
Görüldüğü gibi işlem yoğunluğu arttıkça race condition oluşma şansı da o kadar artıyor. Çünkü uzun süre çalışmakta olan birden fazla sürecin eş olması için daha fazla zaman tanımış oluyoruz.
Soru
Peki madem bu sorun bir eş zamanlılık problemi. Eğer çalışan benzer bir kod uniprocessor (Tek işlemci yahut çekirdek) bir sistemde çalışsaydı bu sorundan otomatik olarak kurtulmuş olur muyduk? Çünkü ortada eşzamanlı çalışan herhangi ikincil bir işlemci olmadığından mantık olarak bunun olmaması gerekir.
Cevabı maalesef hayır. Uniprocessor bir sistemde çalışıyor olmamız bizi bu durumdan kurtaramıyor. Peki bir işlemci ile paralel çalışan ikincil bir işlemci olmadığı halde bu durum nasıl oluşur? Bunun cevabı işlemcinin kendisinde değil işletim sisteminin tasarımında saklıdır. Yazının en başında bu konuya daha sonra değineceğimden bahsetmişim. İşte bu nokta bundan bahsetmek için uygun bir yer. Bunu anlamak için modern sayılabilecek işletim sistemlerinin sağladığı multi-tasking, multi-threading gibi özelliklerin temel de olsa anlaşılabilmesi gerekir.
İşletim sistemleri tekli işlemcilerle de multi-threaded, multi-tasking çalışabilme kapasitesine sahiplerdi. Bunu da işlemciden bağımsız bir çipin belli aralıklarda bir interrupt (kesme) oluşturmasıyla sağlamaktaydılar. Hoş günümüzde de işler benzer şekilde yürür ancak eskisi kadar ilkel değildir artık. Bu bağımsız aygıt (PIC) bir interrupt ürettiğinde işlemci çalışmakta olduğu kodu durdurup interrupt handler rutinine dallanır. İşletim sistemi de bu handler kısmına kendi özel kodlarını yerleştirerek çalışmayı bekleyen başka bir thread’i listeden seçip işlemci üzerine bırakarak çalışmasını sağlamaktadır. Bu şekilde bir döngü halinde tek işlemci üzerinde zaman paylaşımlı birden çok iş parçacığını çalıştırmak mümkün olmaktaydı. Bu işlem bizim algılayamayacağımız hızlarda yapıldığından bizlerde birçok program aynı anda çalışıyormuş izlenimi oluşturmaktadır. Halbuki olan her programa ait kodların sırayla çalıştığıdır.
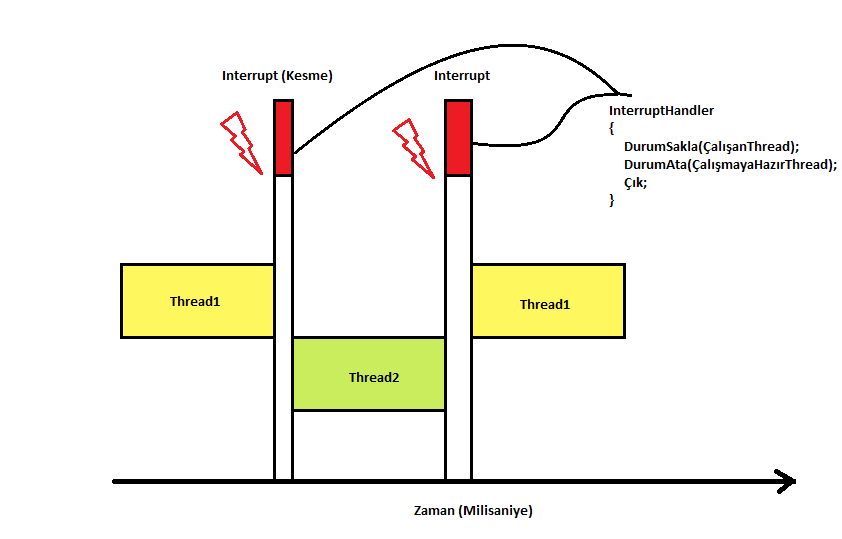
Yukarıdaki görsel bu işlemin basitçe grafiğe dökülmüş halidir. Şimdi belli aralıklarla çalışan kodlar kesilip yerlerine başka kodlar çalıştırılabiliyorsa (Preemption) bu durum aynı kodu çalıştıran birden fazla Thread’in başna da gelebilir gayet. Ancak başımızda eşzamanlı çalışan bir donanım olmadığından oluşan durum eşzamanlılık çakışmasından ziyade yanlış yerde kesintiye uğrama tehlikesidir. Bu yüzden race condition uniprocessor sistemlerde kolay oluşmaz ancak kesinlikle oluşmayacağının garantisi de verilemez. En yukarıdaki örneği Uniprocessor açıdan yorumlarsak
Thread1: REG1 = [g_sharedValue] /\/\/\PREEMPTION/\/\/\ REG1 = REG1 + 1 [g_sharedValue} = REG1 Thread2: REG1 = [g_sharedValue] REG1 = REG1 + 1 /\/\/\PREEMPTION/\/\/\ [g_sharedValue} = REG1
Aynı kodu çalıştıran iki farklı thread’in farklı noktalarda kesilmesi kodun sonraki adımlarında yine istenmeyen sonuçlara sebebiyet verebilecektir.
Bunu gözlemlemek için demo programına tekrar dönelim. Aynı kodu tek çekirdek üzerinde çalışacak şekilde zorlayıp nasıl şartlar altında ne sıklıkla race condition oluşabilir inceleyelim.
Testi başlangıç olarak önceki multi-core versiyonda race condition’a sebebiyet veren senaryodan başlatalım.
Test#1) Program Opsiyonları: -w 10 -i 2000 -su -tc 5
Test will be running using 10 Worker Threads with 2000 iteration per worker. Uniprocessor simulation is on, and Worker distribution is off === Test#1 is staring === === Test#1 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#2 is staring === === Test#2 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#3 is staring === === Test#3 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#4 is staring === === Test#4 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#5 is staring === === Test#5 finished. Expected Value: 0, Actual sharedValue : 0 === All done
Test#2) Program Opsiyonları: -w 150 -i 8000 -su -tc 5
Test will be running using 150 Worker Threads with 8000 iteration per worker. Uniprocessor simulation is on, and Worker distribution is off === Test#1 is staring === === Test#1 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#2 is staring === === Test#2 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#3 is staring === === Test#3 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#4 is staring === === Test#4 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#5 is staring === === Test#5 finished. Expected Value: 0, Actual sharedValue : 0 === All done
Halen iyi görünüyor. Peki aynı komutu birkaç kez daha versek durum yine aynı mı olacak? Ben farklı bir sonuç alana kadar birkaç kez daha aynı komutu kullandım. Çok uzun sürmedi 3. denememde farklı bir sonuç aldım.
Test will be running using 150 Worker Threads with 8000 iteration per worker. Uniprocessor simulation is on, and Worker distribution is off === Test#1 is staring === === Test#1 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#2 is staring === === Test#2 finished. Expected Value: 0, Actual sharedValue : 0 === === Test#3 is staring === === Test#3 finished. Expected Value: 0, Actual sharedValue : 1 === === Test#4 is staring === === Test#4 finished. Expected Value: 0, Actual sharedValue : 1 === === Test#5 is staring === === Test#5 finished. Expected Value: 0, Actual sharedValue : 0 === All done
İşte şanssız anımız. Tek çekirdek üzerinde istenmeyen sonuç elde edebildik. Şanssızdık çünkü yeteri kadar thread’i yeteri kadar süre scheduler (zamanlayıcı) üzerinde aktif olarak tuttuk. Artık öyle bir ana geldi ki scheduler o çekirdek üzerinde sıklıkla prosesimize ait thread’leri zamanlamaya başladı ve aynı paylaşımlı kaynağa ulaşmaya çalışan düşük seviye operasyon da aynı noktada yoğun olarak bulunduğundan beklenmeyen bir sonuç kaçınılmaz oldu. Biz bu şekilde sistemi biraz buna zorladık. Buradaki amaç bu problemin önlem alınmadığında her şekilde ortaya çıkabileceğiydi.
Programcıların görevi ihtimaller ne kadar az olursa olsun bunları sıfıra kesin bir şekilde indirmek olmalıdır. Bu tip sorunların önüne geçmek içinse çeşitli senkronizasyon ve kilit yöntemleri kullanılmalıdır. Bu yazı yeterince uzun olduğundan eğer kısa sürede tekrar vakit bulabilirsem bu konunun devamı niteliğinde senkronizasyon ve kilit mekanizmaları hakkında bilgiler verip güvenli şekilde concurrent programlamanın ipuçlarını bilgim dahilinde paylaşmaya çalışacağım.
Zaman ayırdığınız için teşekkürler.
bu güzel makale için teşekkürler.
devami da gelir umarim :)
оптовая продажа семян – https://lepestok.su
tesekkurler
ellerinize saglık gayet aciklayici bir makale olmus
Harika bir yazı olmuş, teşekkürler
You’ve done an impressive work on your website in covering the topic. I am working on content about Web Development and thought you might like to check out YR4 and let me what you think.
An interesting topic and I’m glad to come across your page where I found some helpful insights. Check out my website UY8 too, if you need additional resources about Airport Transfer.
Hey, I enjoyed reading your posts! You have great ideas. Are you looking to get resources about Airport Transfer or some new insights? If so, check out my website FQ5
Superb layout and design, but most of all, concise and helpful information. Great job, site admin. Take a look at my website ZH5 for some cool facts about Thai-Massage.